
什么是分词器?
英文名叫Analyzer:将一段文本,按照一定逻辑,分析成多个词语的一种工具。
如:床前明月光 --> 床、月、明月、月光、光。
ES默认内置了分词器,但是对中文进行分词很不友好!处理的方式:一个字一个词。
这样我们古诗就变成 床、前、明、月、光了。假如我们搜索 “月光”,就很尴尬只能通过合并集来得到"月光"这个词汇。下图就是相关的分词结果:
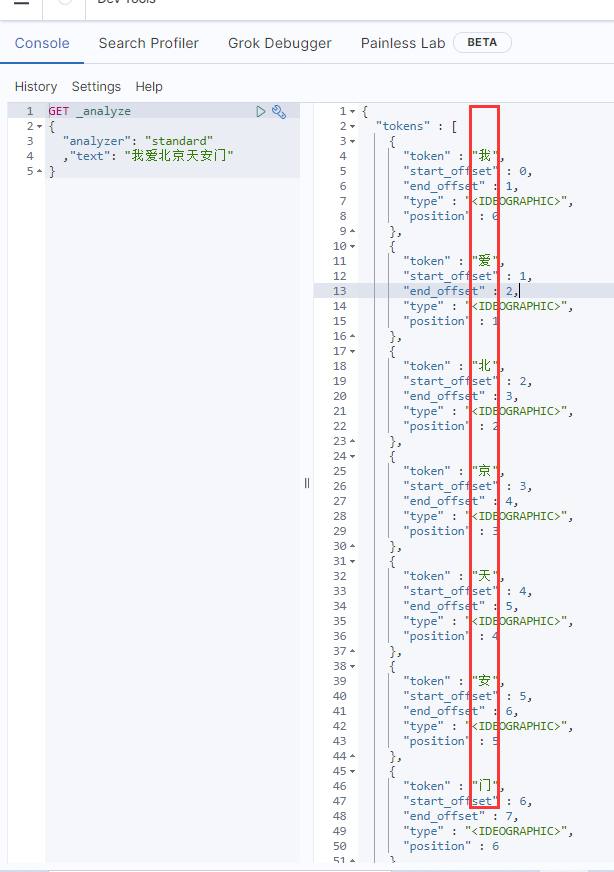
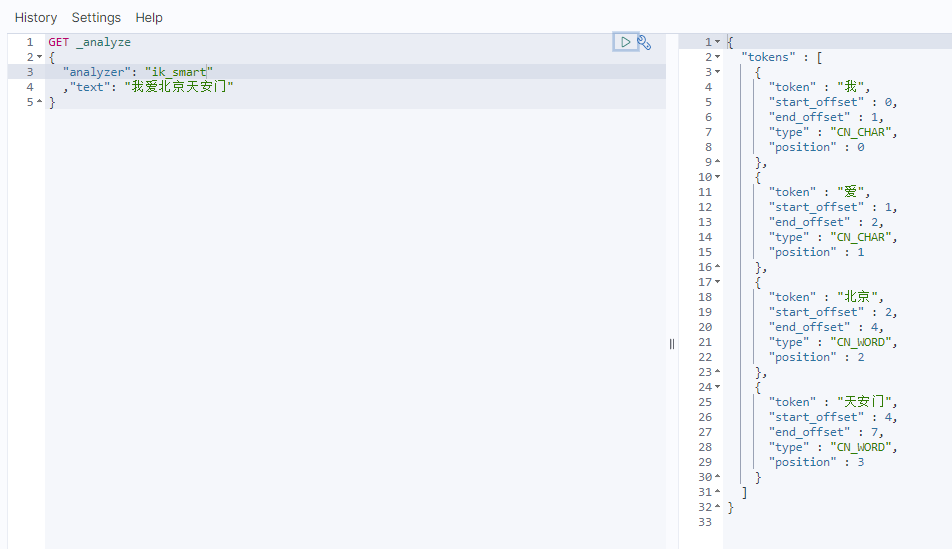
左边 看到token 就是一个字,一个字的。
所以,我们就需要使用我们 IK分词器
IK 分词器:IKAnalyzer是一个开源的,轻量级的基于Java语言开发的中文分词工具包
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
记得 下载相同版本的ES 才可以使用。
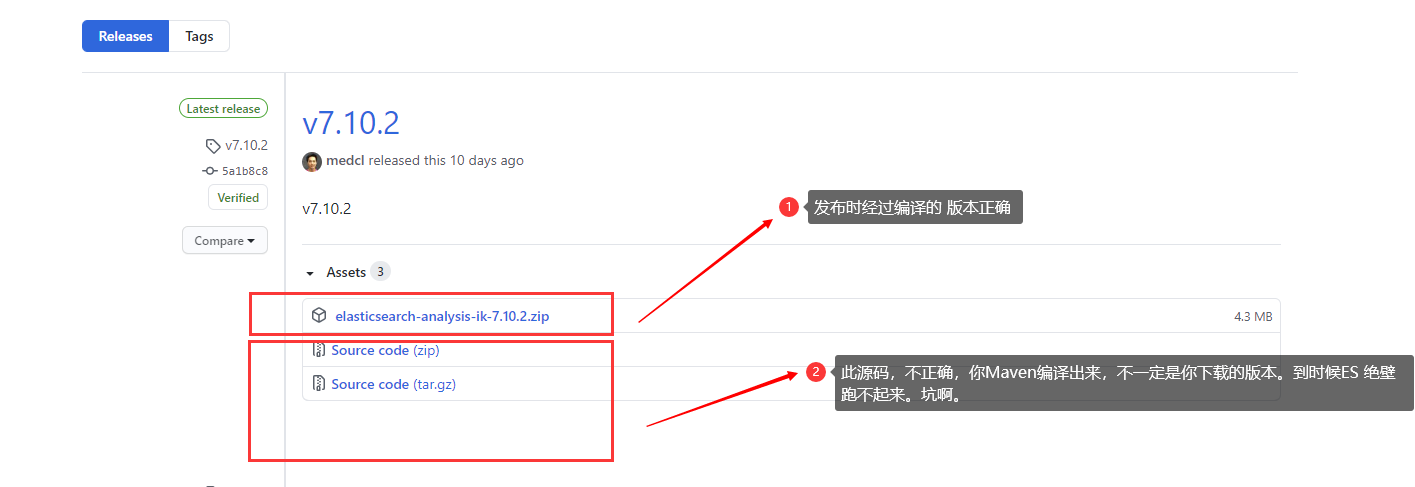
他娘的,这里注意一下。发布的源码,经过编译,不一定是你下载的版本。太他妈坑了。所以,咱们不编译,直接拿过来用。
好处:
- 每秒60万字的处理能力
- 支持自定义拓展用户词典
设置 软连接 (相当于 Windows环境下的 快捷方式)Ln 不是 In
ln -s 文件位置 快捷方式的放位置/名字(可省略)例如 不加名字
ln -s /home/elasticsearch-7.10.2 /zhuomian/将来在/zhuomian下 输入 cd/elasticsearch-7.10.2 就可以自动进入
例如 加名字
ln -s /home/elasticsearch-7.10.2 /zhuomian/es将来在/zhuomian下 输入 cd/es 就可以自动进入
回到正文!!!
在elasticsearch-7.10.2/plugins 下 并创建一个文件夹ik
mkdir ik将github下载下来的现成的插件 复制进去
搞好了。直接 lsof -i:9200 然后 杀死ES 在开启ES。
安装完成。
使用
原来使用 standard 是 单个单词(汉字)进行分词。
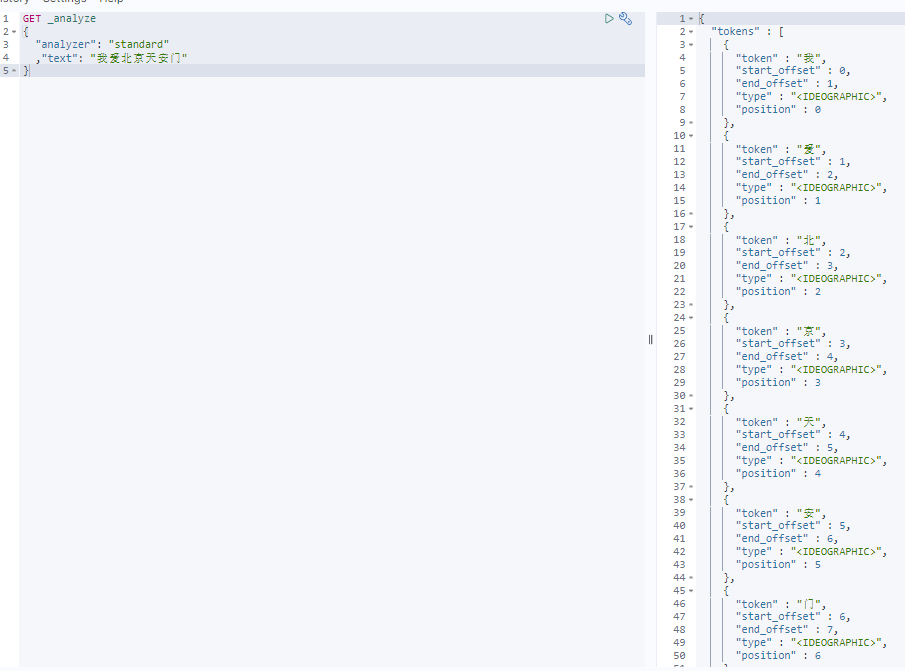
现在引入 中文分词插件了。就多了2种模式 进行 分析、分词
ik_smart:粗粒度 (分的相对不那么细,但因为分词少,效率高)
- ik_max_word:细粒度 (分的更细,但会造成分词次数加多)

使用 ik_smart 粗粒度
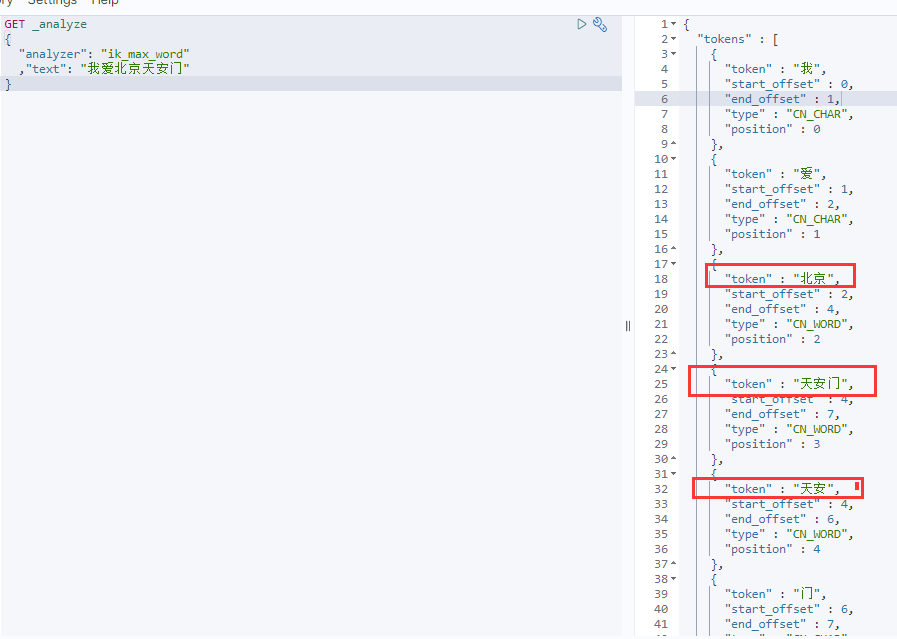
使用 ik_max_word 细粒度 分词结果。
完了。
使用分词器
查询方式有2种
- term:词条查询
- match:全文匹配

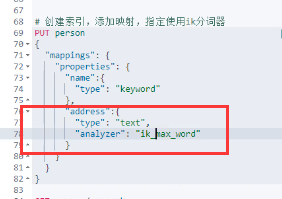
强调:在创建映射的时候,关于Text字段 一定要指定我们的中文分词器,不然就是使用默认standard 进行分析,分词。
特殊说明:
上述文章均是作者实际操作后产出。烦请各位,请勿直接盗用!转载记得标注原文链接:www.zanglikun.com
第三方平台不会及时更新本文最新内容。如果发现本文资料不全,可访问本人的Java博客搜索:标题关键字。以获取最新全部资料 ❤
免责声明: 本站文章旨在总结学习互联网技术过程中的经验与见解。任何人不得将其用于违法或违规活动!所有违规内容均由个人自行承担,与作者无关。
第三方平台不会及时更新本文最新内容。如果发现本文资料不全,可访问本人的Java博客搜索:标题关键字。以获取最新全部资料 ❤
免责声明: 本站文章旨在总结学习互联网技术过程中的经验与见解。任何人不得将其用于违法或违规活动!所有违规内容均由个人自行承担,与作者无关。
评论(0)