

MongoDB 官方:https://www.mongodb.com/
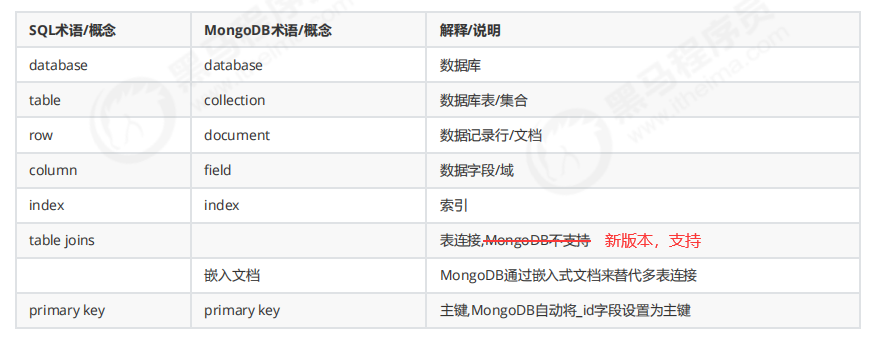
MongoDB 简介
MongoDB是一个开源、高性能、无模式的文档型数据库,当初的设计就是用于简化开发和方便扩展,是NoSQL数据库产品中的一种。是最 像关系型数据库(MySQL)的非关系型数据库。 它支持的数据结构非常松散,是一种类似于 JSON 的 格式叫BSON。我们完全可以以JSON理解。
横向概念理解
如何针对使用MongoDB进行技术选型?
- 开发新应用,需求会变,数据模型无法确定,想快速迭代开发
- 应用需要2000-3000以上的读写QPS(更高也可以)
- 应用需要TB甚至 PB 级别数据存储
- 应用要求存储的数据不丢失 应用需要99.999%高可用 应用需要大量的地理位置查询、文本查询
- 等等
操作MongoDB 之前 先了解一下 连接MongoDB
首先配置文件中,有2处需要设置
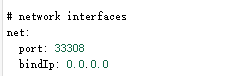
port:占用的端口
bindIp:0.0.0.0 允许登录 ,127.0.0.1 只代表本机登录,也可以指定IP登录。
配置好了相关,重启MongoDB 注意云服务器的安全组开放,或者服务器的防火墙开放等
操作
查看所有的数据库
show dbs 或show databases使用数据库 (如果数据库不存在,就自动创建)
use 数据库名查看当前使用的数据库
db
//MongoDB 中默认的数据库为 test,如果你没有选择数据库,集合将存放在 test 数据库中。删除数据库
db.dropDatabase("数据库名")(显示)创建集合(表)
db.createCollection(name)查看当前库中的集合(表)
show collections 或show tables隐式创建集合(表) / 添加文档
db.集合名.insert(BSON格式的数据)
//返回 WriteResult({ "nInserted" : 1 }) 就是成功批量插入文档
db.collection.insertMany( [ 表1 , 表2], { writeConcern: <document>, ordered: <boolean> } )
说明:
表1 ,表2 代表的集合名
writeConcern 代表文档名,可以数组形式
ordered 是否有序插入,布尔值查询文档数据
db.comment.find() 或 db.comment.find({})
db.collection.find(条件, 结果集格式) 条件,结果集格式都可以不传递
例如: db.comment.find({userid:"1003"},{userid:1,nickname:1})
最终结果就是:
{ "_id" : "4", "userid" : "1003", "nickname" : "凯撒" }
{ "_id" : "5", "userid" : "1003", "nickname" : "凯撒" }
说明:
_id 是默认带的
如果不想要,可以将修改为 db.comment.find({userid:"1003"},{userid:1,nickname:1,_id:0})
结果就是:
{ "userid" : "1003", "nickname" : "凯撒" }
{ "userid" : "1003", "nickname" : "凯撒" }删除文档数据
db.集合名.remove(条件)
全部删除 如下:
db.comment.remove({})修改文档数据
db.collection.update(query, update, options)
或 db.collection.update(
<query>,
<update>,
{ upsert: <boolean>, multi: <boolean>, writeConcern: <document>, collation: <document>, arrayFilters: [ <filterdocument1>, ... ], hint: <document|string> // Available starting in MongoDB 4.2 } )
说明:
query 条件
update 更新的内容
options 参数
实际案例:
覆盖的修改 :只保留likenum 和_id 字段,其他全部消失
db.表名.update({_id:"1"},{likenum:NumberInt(1001)})
局部修改:使用$set:{}修改器修改,才是真正的修改
db.表名.update({_id:"2"},{$set:{likenum:NumberInt(889)}})
批量修改
db.comm表名nt.update({userid:"1003"},{$set:{nickname:"凯撒大帝"}},{multi:true})
列值增长修改(场景如点赞)用 $inc 运算符来实现。
db.表名.update({_id:"3"},{$inc:{likenum:NumberInt(1)}})计数查询
db.collection.count(条件, 参数) 条件、参数可以不传入
例如:
db.表名.count({userid:"1003"}) == 查询userid = 1003 的所有记录数量分页查询
db.表名.find().skip(数字).limit(数字)
skip 跳过数量
limit 每页数量
我们依旧以我们正常的分页参数计算,pageNumber = y,pageSize = x,
场景: 页数范围 每页2个 假设等于x
第一页 0-2 skip(0),limit(2)
第二页 2-4 skip(2),limit(2)
第三页 4-6 skip(4),limit(2)
第四页 6-8 skip(6),limit(2)
.... ... ....
第n页 x*(n-1)-x*n skip(x*(n-1)).limit(x)
第y页 的数据 skip(x*(y-1)).limit(x)
我们的正常结果是
正常业务代码是:
skip( pageSize * (pageNum - 1) ).limit( pageSize )
当skip(), limilt(), sort()三个放在一起执行的时候,执行的顺序是先 sort(), 然后是 skip(),最后是显示的 limit(),和命令编写顺序无关。排序查询
db.表名.find(查询条件).sort({字段,1})
1 代表升序 -1 代表降序正则匹配查询 自己百度查询
比较查询
举例:> 等于 > ,其他自己研究
db.集合名称.find({ "field" : { $gt: value }}) // 大于: field > value
db.集合名称.find({ "field" : { $lt: value }}) // 小于: field < value
db.集合名称.find({ "field" : { $gte: value }}) // 大于等于: field >= value
db.集合名称.find({ "field" : { $lte: value }}) // 小于等于: field <= value
db.集合名称.find({ "field" : { $ne: value }}) // 不等于: field != value包含查询 等价于sql in(1003,1004)
db.comment.find({userid:{$in:["1003","1004"]}})条件连接查询
$and:[ { },{ },{ } ]
$or:[ { },{ },{ } ]常用总结:
选择切换数据库:use articledb
插入数据:db.comment.insert({bson数据})
查询所有数据:db.comment.find();
条件查询数据:db.comment.find({条件})
查询符合条件的第一条记录:db.comment.findOne({条件})
查询符合条件的前几条记录:db.comment.find({条件}).limit(条数)
查询符合条件的跳过的记录:db.comment.find({条件}).skip(条数)
修改数据:db.comment.update({条件},{修改后的数据}) 或db.comment.update({条件},{$set:{要修改部分的字段:数据})
修改数据并自增某字段值:db.comment.update({条件},{$inc:{自增的字段:步进值}})
删除数据:db.comment.remove({条件})
统计查询:db.comment.count({条件})
模糊查询:db.comment.find({字段名:/正则表达式/})
条件比较运算:db.comment.find({字段名:{$gt:值}})
包含查询:db.comment.find({字段名:{$in:[值1,值2]}})或db.comment.find({字段名:{$nin:[值1,值2]}})
条件连接查询:db.comment.find({$and:[{条件1},{条件2}]})或db.comment.find({$or:[{条件1},{条件2}]})MongoDB索引
种类
- 单字索引
- 复合索引:复合索引中列出的字段顺序具有重要意义:例如,如果复合索引由 { userid: 1, score: -1 } 组成,则索引首先按userid正序排序,然后 在每个userid的值内,再在按score倒序排序。
- 其他索引 :地理空间索引(Geospatial Index)、文本索引(Text Indexes)、哈希索引(Hashed Indexes)。
地理空间索引(Geospatial Index)
为了支持对地理空间坐标数据的有效查询,MongoDB提供了两种特殊的索引:返回结果时使用平面几何的二维索引和返回结果时使用球面 几何的二维球面索引。
文本索引(Text Indexes)
MongoDB提供了一种文本索引类型,支持在集合中搜索字符串内容。这些文本索引不存储特定于语言的停止词(例如“the”、“a”、“or”), 而将集合中的词作为词干,只存储根词。
哈希索引(Hashed Indexes)
为了支持基于散列的分片,MongoDB提供了散列索引类型,它对字段值的散列进行索引。这些索引在其范围内的值分布更加随机,但只支 持相等匹配,不支持基于范围的查询。
查看索引
db.collection.getIndexes()
创建单个索引
db.comment.createIndex({userid:1})
创建复合索引
db.comment.createIndex({userid:1,nickname:-1})
删除索引
db.collection.dropIndex()
删除全部索引
db.collection.dropIndexes()
查看索引是否生效
db.collection.find(query,options).explain(options)
例如:db.comment.find({userid:"1003"}).explain() //关键点看: "stage" : "COLLSCAN", 表示全集合扫描
当查询条件和查询的投影仅包含索引字段时,MongoDB直接从索引返回结果,而不扫描任何文档或将文档带入内存。 这些覆盖的查询可以
非常有效。关于MongoDB的Explain https://www.zanglikun.com/4661.html
特殊说明:
上述文章均是作者实际操作后产出。烦请各位,请勿直接盗用!转载记得标注原文链接:www.zanglikun.com
第三方平台不会及时更新本文最新内容。如果发现本文资料不全,可访问本人的Java博客搜索:标题关键字。以获取最新全部资料 ❤
免责声明: 本站文章旨在总结学习互联网技术过程中的经验与见解。任何人不得将其用于违法或违规活动!所有违规内容均由个人自行承担,与作者无关。
第三方平台不会及时更新本文最新内容。如果发现本文资料不全,可访问本人的Java博客搜索:标题关键字。以获取最新全部资料 ❤
免责声明: 本站文章旨在总结学习互联网技术过程中的经验与见解。任何人不得将其用于违法或违规活动!所有违规内容均由个人自行承担,与作者无关。
评论(0)