
各大厂商选择的消息队列的应用不尽相同,市面上也有很多的产品,为了更好的适应就业,自己必须靠自己去学习,本篇文章讲述的就是,Kafka 消息队列
Kafka 简介:
是一款分布式,基于 发布订阅模式的 消息队列产品,主要应用于大数据实时处理领域。
使用Kafka的好处?
好处就是使用消息队列的好处:削峰填谷、异步解耦
使用kafka的条件
依赖Zookeeper(帮助Kafka 集群存储信息,帮助消费者存储消费的位置信息)
下载Kafka
安装Kafka
启动 zookeper
进入bin目标,直接
启动
./kafka-server-start.sh -daemon ../config/server.properties
参数说明
-daemon 的作用是后台启动,不占用当前终端打印台
../config/server.properties 是指定配置文件,不指定配置文件不行
停止 Kafka
./kafka-server-stop.sh
查看是否启动成功
jps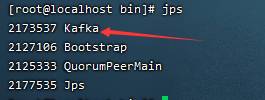
启动成功了!
尚硅谷 在这里 提到了 shell 脚本 https://www.bilibili.com/video/BV1a4411B7V9?p=6&spm_id_from=pageDriver 不会,需要补充学习一下 16分钟之后
这里 补充一下配置文件的说明
- zookeeper.connect 指明Zookeeper主机地址,如果zookeeper是集群则以逗号隔开,如: 172.6.14.61:2181,172.6.14.62:2181,172.6.14.63:2181
- listeners 监听列表,broker对外提供服务时绑定的IP和端口。多个以逗号隔开,如果监听器名称不是一个安全的 协议, listener.security.protocol.map也必须设置。主机名称设置0.0.0.0绑定所有的接口,主机名称为 空则绑定默认的接口。如:PLAINTEXT://myhost:9092、SSL://:9091 CLIENT://0.0.0.0:9092、REPLICATION://localhost:9093
- broker.id broker的唯一标识符,如果不配置则自动生成,建议配置且一定要保证集群中必须唯一,默认-1
- log.dirs 日志数据存放的目录,如果没有配置则使用log.dir,建议此项配置。
- message.max.bytes 服务器接受单个消息的最大大小,默认1000012 约等于976.6KB。
命令行操作
一台机器只能拥有一个副本 即replication-factor
增
topic 主题名称,partitions 分区数,replication-factor 备份数
./kafka-topics.sh --create --zookeeper 127.0.0.1:2181 --topic first --partitions 2 --replication-factor 1
./kafka-topics.sh --create --zookeeper 127.0.0.1:2181 --topic heima001 --partitions 2 --replication-factor 1
查
./kafka-topics.sh --list --zookeeper 127.0.0.1:2181

此时 日志里就会出现数据
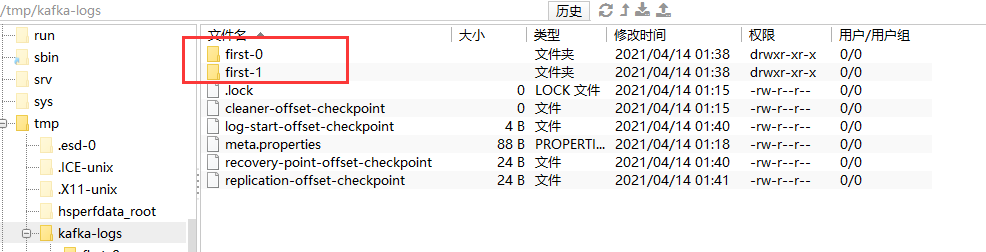
删
[root@localhost bin]# ./kafka-topics.sh --delete --zookeeper 127.0.0.1:2181 --topic first
下面提示
Topic first is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.此时 去看数据
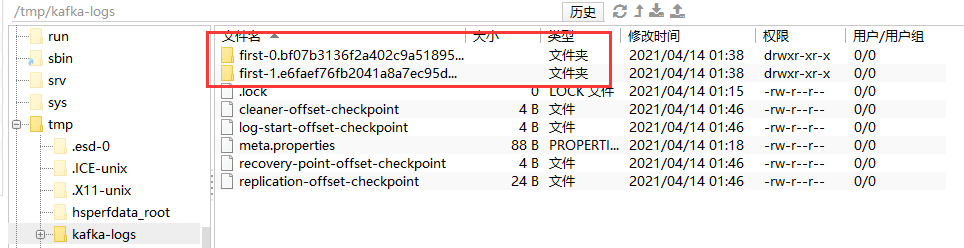
当在此添加主题相同名字 相同分区的、相同的备份 主题时些数据才会被清除
查看tipics信息
./kafka-topics.sh --describe --zookeeper 127.0.0.1:2181 --topic first1
读数据
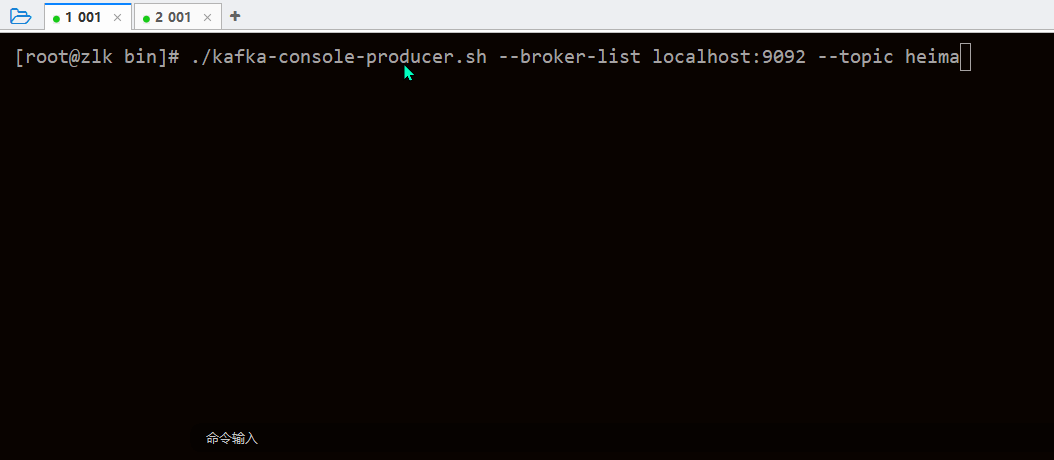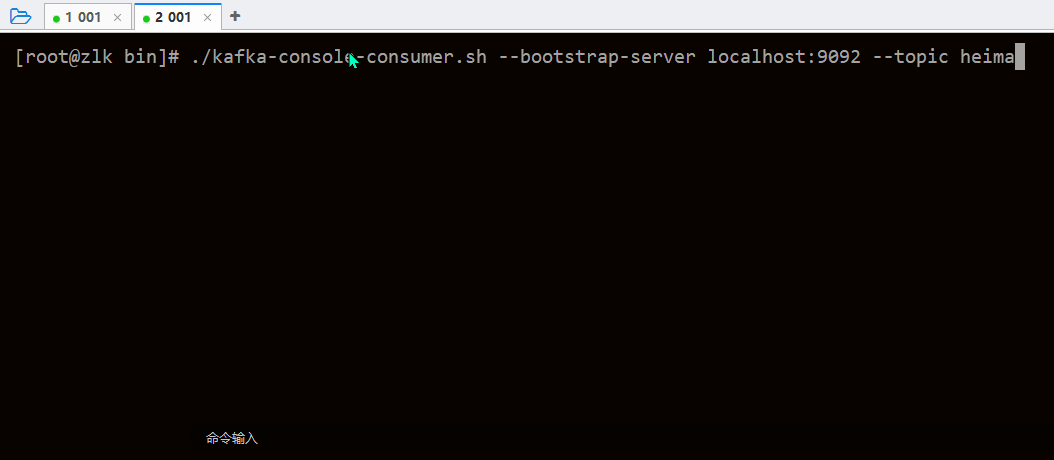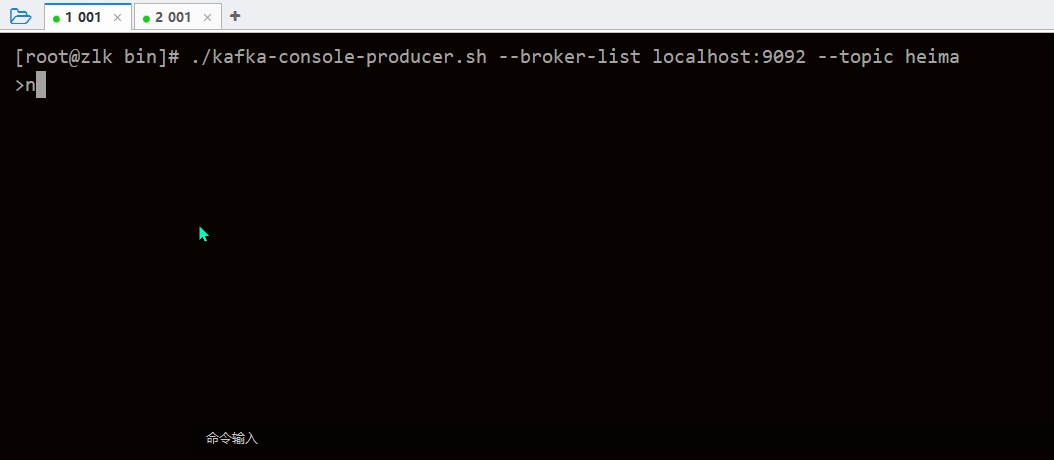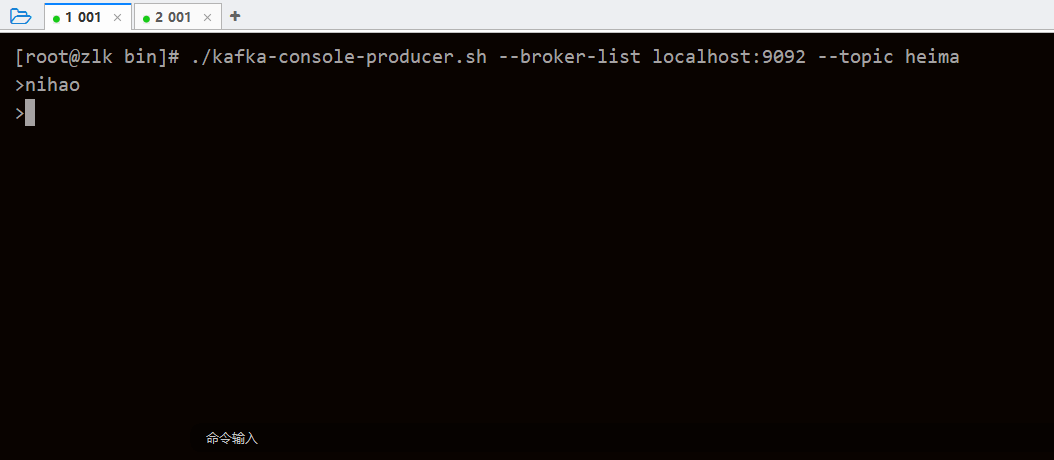
/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic heima发送数据
./kafka-console-producer.sh --broker-list localhost:9092 --topic heima读、写使用如图
listeners=PLAINTEXT://0.0.0.0:9092生产者详解:
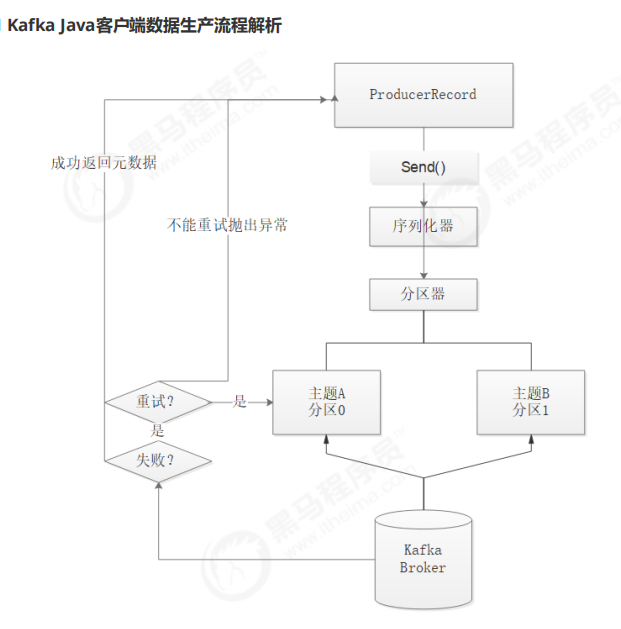
①、首先要构造一个 ProducerRecord 对象,该对象可以声明主题Topic、分区Partition、键 Key以及 值 Value,主题和值是必须要声明的,分区和键可以不用指定。
②、调用send() 方法进行消息发送。
③、因为消息要到网络上进行传输,所以必须进行序列化,序列化器的作用就是把消息的 key 和 value对象序列化成字节数组。
④、接下来数据传到分区器,如果之间的 ProducerRecord 对象指定了分区,那么分区器将不再做 任何事,直接把指定的分区返回;如果没有,那么分区器会根据 Key 来选择一个分区,选择好分区之 后,生产者就知道该往哪个主题和分区发送记录了。
⑤、接着这条记录会被添加到一个记录批次里面,这个批次里所有的消息会被发送到相同的主题和 分区。会有一个独立的线程来把这些记录批次发送到相应的 Broker 上。
⑥、Broker成功接收到消息,表示发送成功,返回消息的元数据(包括主题和分区信息以及记录在 分区里的偏移量)。发送失败,可以选择重试或者直接抛出异常。
同步发送
producer.send(record)
异步发送 (相当于单独开线程去发送,不会影响主线程)
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null) {
System.out.println(metadata.partition() + ":" + metadata.offset());
}
}
});
序列化器
消息要到网络上进行传输,必须进行序列化,而序列化器的作用就是如此。 Kafka 提供了默认的字符串序列化器(org.apache.kafka.common.serialization.StringSerializer), 还有整型(IntegerSerializer)和字节数组(BytesSerializer)序列化器,这些序列化器都实现了接口 (org.apache.kafka.common.serialization.Serializer)基本上能够满足大部分场景的需求。
第三方平台不会及时更新本文最新内容。如果发现本文资料不全,可访问本人的Java博客搜索:标题关键字。以获取最新全部资料 ❤
免责声明: 本站文章旨在总结学习互联网技术过程中的经验与见解。任何人不得将其用于违法或违规活动!所有违规内容均由个人自行承担,与作者无关。
评论(0)