
Elements介绍
Chrome 的 Element 是 Chrome 浏览器内置的开发者工具之一,它提供了一种方便的方式来检查和调试网页的 HTML 结构、CSS 样式和 DOM 元素。
以下是 Chrome 的 Element 工具的一些主要功能:
- 元素检查:使用 Element 工具,您可以轻松地检查网页上的任何元素。只需在 Elements 面板中选择要检查的元素,即可查看其 HTML 结构、CSS 样式和应用的样式规则。
- 实时编辑:您可以直接在 Element 工具中对网页的 HTML 和 CSS 进行实时编辑。通过双击元素或样式属性,您可以修改它们的值并即时看到效果。这对于调试和快速测试样式更改非常有用。
- 盒模型查看:Element 工具提供了一个方便的盒模型查看器,可以显示元素的尺寸、边距、填充和边框等信息。这有助于了解元素在页面布局中的位置和大小。
- CSS 样式检查:您可以查看应用于元素的所有 CSS 样式规则,并检查每个样式属性的值。还可以查看样式的来源,包括内联样式、嵌入式样式和外部样式表。
- 事件监听器:Element 工具允许您查看和调试元素上绑定的事件监听器。您可以查看元素上注册的事件类型、事件处理函数和事件触发情况,以帮助您识别和解决与事件相关的问题。
- 网络请求:除了检查和调试 HTML 和 CSS,Element 工具还提供了一个网络面板,用于监视和分析网页的网络请求。您可以查看每个请求的详细信息、请求头、响应内容和性能指标等。
- 设备模拟:Element 工具提供了一个方便的设备模拟器,可以模拟不同的设备类型和屏幕尺寸。这样您可以查看网页在不同设备上的外观和响应情况,以进行响应式设计和开发。
Chrome 的 Element 工具是开发者在调试和优化网页时的强大助手。它提供了丰富的功能和实时编辑能力,使开发人员能够更好地理解和调整网页的结构和样式。
要打开 Chrome 的 Element 工具,请右键单击网页上的任何元素,然后选择 "检查" 或 "审查元素"。您也可以使用快捷键 Ctrl+Shift+C(Windows/Linux)或 Command+Option+C(Mac)来打开 Element 工具。
「拓展」在Html如何定位一个元素
- 标签名定位:使用元素的标签名作为定位器,例如
<div>、<p>、<a>等。这种方法适用于您只需要获取某个类型的元素,而不需要考虑其他属性或层级关系。 - ID 定位:使用元素的唯一标识符(ID)作为定位器,例如
<div id="myDiv">。可以通过getElementById方法或选择器#来定位具有特定 ID 的元素。 - 类名定位:使用元素的类名作为定位器,例如
<div class="myClass">。可以通过getElementsByClassName方法或选择器.来定位具有特定类名的元素。 - 属性定位:使用元素的属性作为定位器,例如
<input type="text">。可以通过选择器[attribute=value]来定位具有特定属性和属性值的元素。 - 层级关系定位:使用元素的层级关系作为定位器,例如
<div><p>Text</p></div>。可以通过选择器parent > child或ancestor descendant来定位特定层级关系的元素。 - CSS 选择器定位:使用 CSS 选择器语法来定位元素,例如
#myId .myClass。可以使用querySelector或querySelectorAll方法来执行 CSS 选择器定位。 - XPath 定位:使用 XPath 表达式来定位元素。可以使用
document.evaluate方法或相关的库(如javax.xml.xpath)来执行 XPath 定位。
总结:我们用于爬虫的好兄弟,更多的是使用CSS选择器定位,以及XPath定位。其他定位方式更多是前端同学自己定位!
操作Elements
我们在浏览器上点击Elements选项会弹出网站当前浏览器渲染内容的源代码
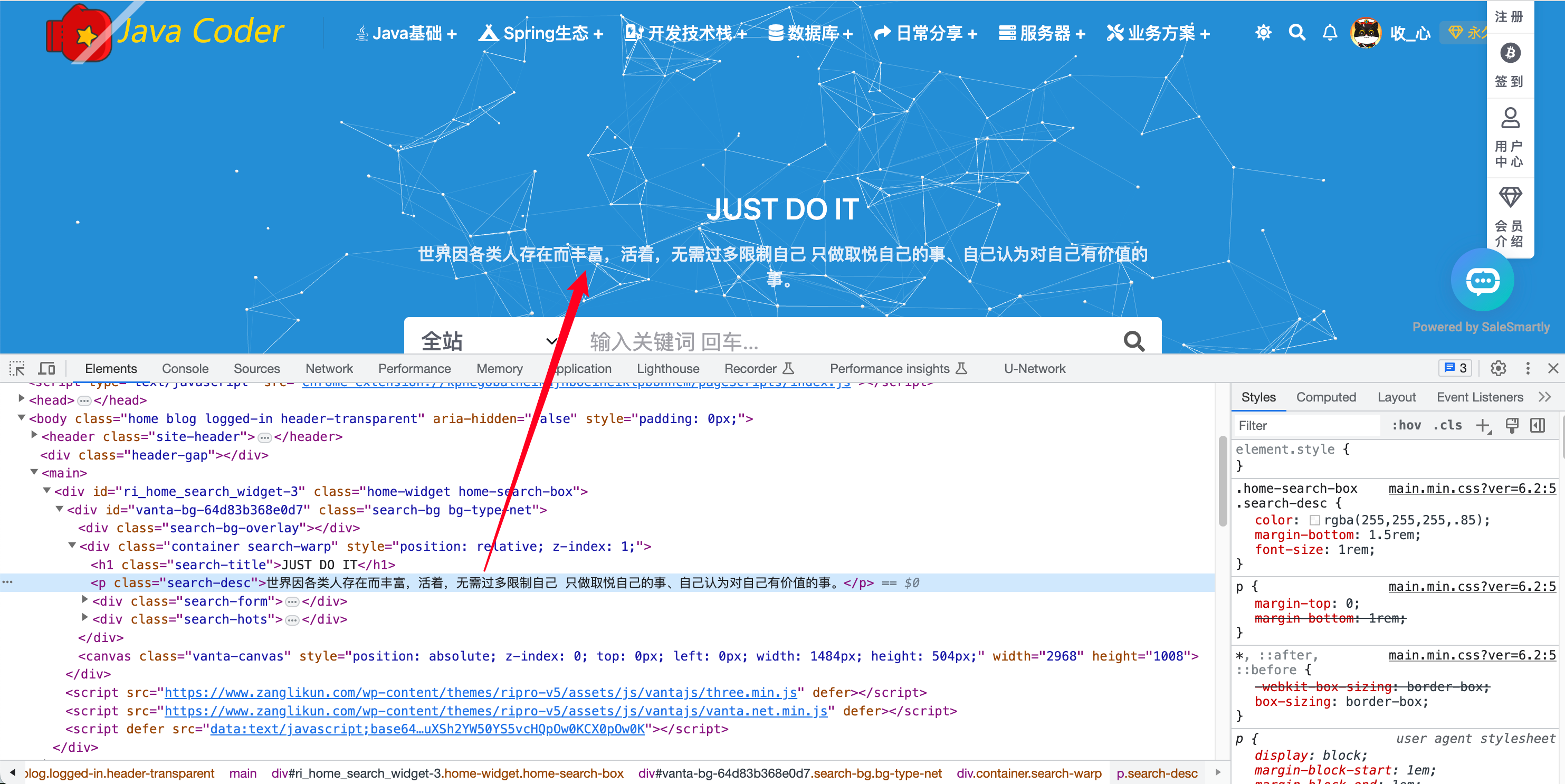
元素检查(这是对爬虫同学最重要的!)
我们可以通过页面元素获取其属性,以便于取爬虫
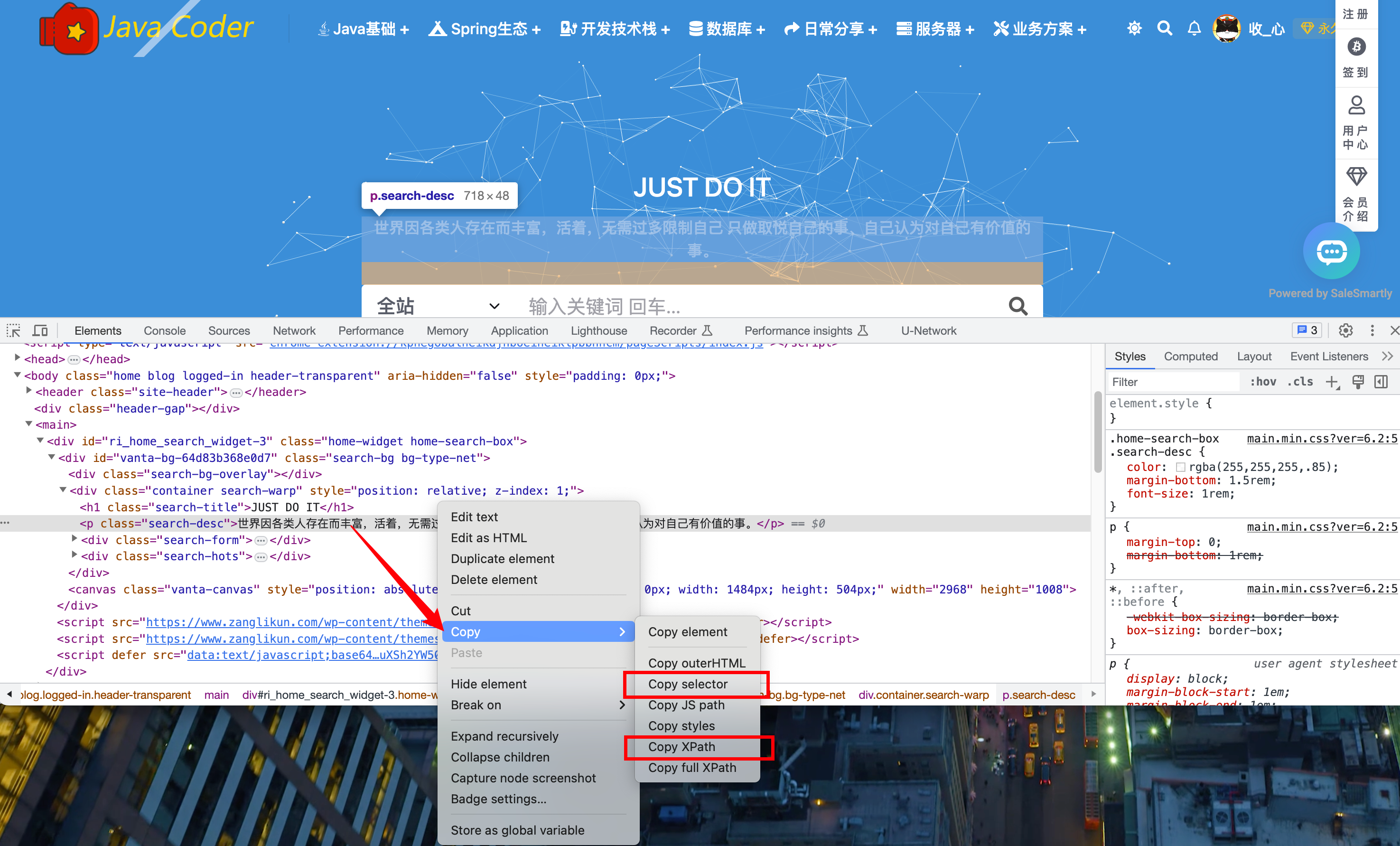
复制的 selector 准确来叫做使用CSS 选择器定位一个元素
本站案例:Jsoup使用selector爬虫:https://www.zanglikun.com/1279.html#%e5%ae%9e%e6%88%98_%e2%80%93_%e8%8e%b7%e5%8f%96html%e6%8c%87%e5%ae%9a%e7%9a%84%e5%85%83%e7%b4%a0%e7%9a%84%e5%86%85%e5%ae%b9
#vanta-bg-64d83b368e0d7 > div.container.search-warp > p复制的 XPath
介绍一下XPath:在 Web 开发中,XPath 常常用于从 HTML 页面中提取数据(爬虫),或者在自动化测试中定位和操作页面元素。
//*[@id="vanta-bg-64d83b368e0d7"]/div[2]/p复制的full XPath
/html/body/main/div[1]/div/div[2]/p样式检查
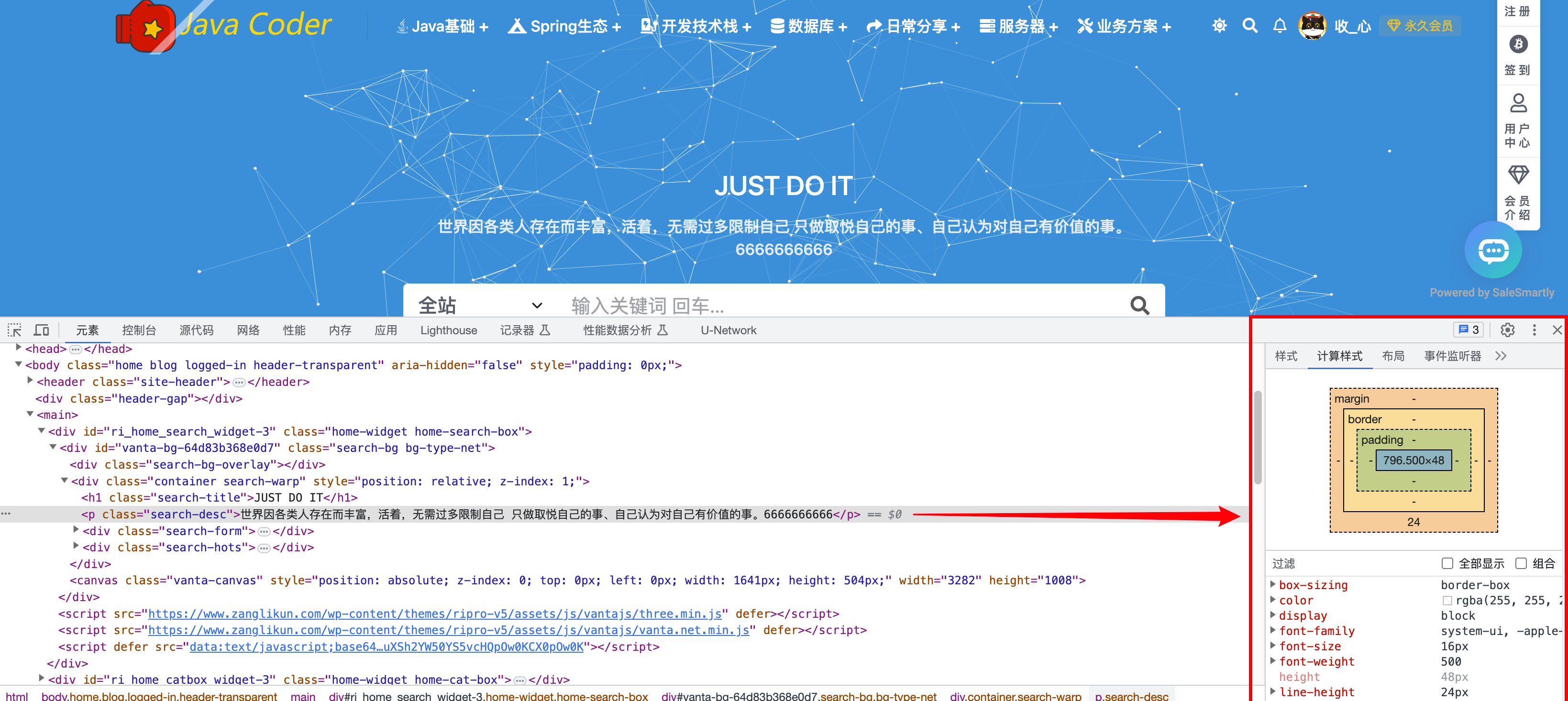
前端同学需要研究,后端几乎用不到这个样式检查。
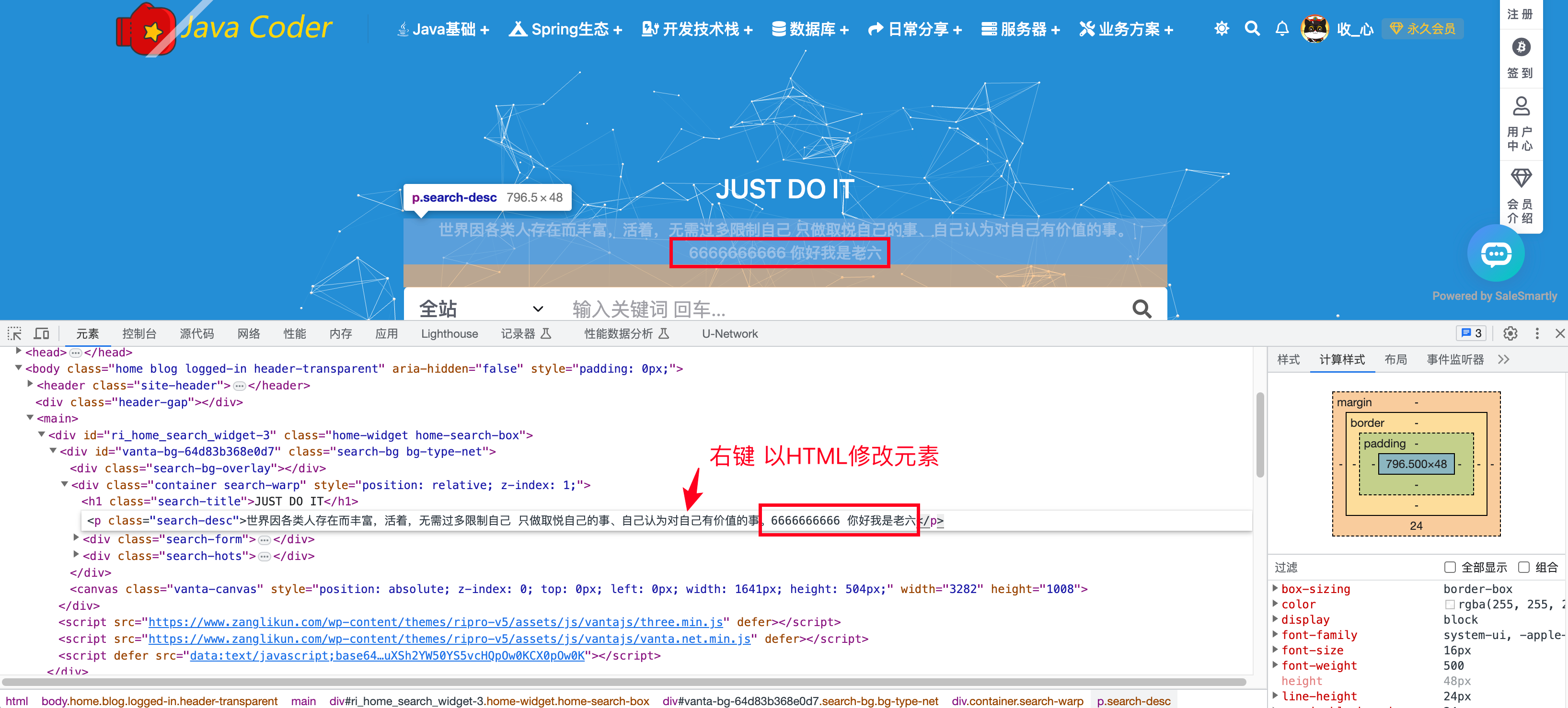
实时编辑
实时编辑最大的作用就是将浏览器input标签type为的password修改为text。别的没啥要说的!
第三方平台不会及时更新本文最新内容。如果发现本文资料不全,可访问本人的Java博客搜索:标题关键字。以获取最新全部资料 ❤
免责声明: 本站文章旨在总结学习互联网技术过程中的经验与见解。任何人不得将其用于违法或违规活动!所有违规内容均由个人自行承担,与作者无关。