

Jsoup:https://jsoup.org/
建议搭配ChatGPT一起使用:https://gpt.zanglikun.com/
什么是XML?
- 是一种标记语言,很类似 HTML
- XML 的设计宗旨是传输数据,而非显示数据
XML的操作类型
1、解析:将xml文档 数据读取到内存中
2、写入:将数据写入xml
解析 XML 方式
- DOM:将标记语言文档,一次性加载进内存,在内存中形成一颗dom数
优点:可以像Dom树一样,对文档进行 curd
缺点:因为一次性加载全部加载,占内存很大
SAX:逐行读取,(读一行,释放前面一行)基于事件驱动的。
优点:不占内存。
缺点:只能读取,不能增删改。
总结:服务端:适合DOM。移动端:内存较小,适合SAX
常见的XML解析器Java库
JAXP
sun公司提供的解析器,支持dom和sax两种思想,官方,性能较烂。
DOM4j
一款非常优秀的解析器,非官方,但是性能更好
jsoup
是一款Java的html解析器,可直接解析某个URL地址、HTML文本内容,他提供了一套非常省力的API。
PULL
Android 操作系统内置解析器。基于sax方式
Jsoup 快速入门
什么是Jsoup?
Jsoup 是一个用于解析、处理和操作 HTML 和 XML 文档的 Java 库。适用于各种场景,如网络爬虫、数据抓取、网页分析等。它的简单易用和强大的功能使得在 Java 中处理网页数据变得更加方便和高效。
白话:会前端的dom树操作逻辑,就能类比出jsoup处理的API
Java 操作Jsoup步骤
- 导入Jsoup相关的Maven依赖坐标
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.3</version>
</dependency>- 获取document对象
- 获取对应的标签 Element对象
- 获取数据
Jsoup初级案例
Jsoup解析本地xml 案例一
这里自己创建一个.xml 文件 源码如下
<?xml version="1.0" encoding="UTF-8" ?>
<!--
1.填写xml文档的根元素
2.引入xsi前缀. xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
3.引入xsd文件命名空间. xsi:schemaLocation="http://www.itcast.cn/xml student.xsd"
4.为每一个xsd约束声明一个前缀,作为标识 xmlns="http://www.itcast.cn/xml"
-->
<students xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.itcast.cn/xml"
xsi:schemaLocation="http://www.itcast.cn/xml student.xsd">
<student number="persion1">
<name>tom</name>
<age>18</age>
<sex>male</sex>
</student>
<student number="persion2">
<name>lucy</name>
<age>30</age>
<sex>female</sex>
</student>
</students>创建好了xml文件,那就上Java代码获取绝对路径 填入下面吧
@Test
public void JsoupDemo1() throws IOException {
Document parse = Jsoup.parse(new File("文件位置\\student.xml"), "utf-8");
Elements name = parse.select("name"); //查询所有 name 标签集合
Element element = name.get(0); // 获取 第一个 name 标签
String text1 = element.text();// 将其转为String
System.out.println(text1); // tom
Elements age = parse.select("age"); //查询所有age标签
String text2 = age.get(1).text(); //将第2个 age 标签1 并转为 String
System.out.println(text2); // 30
}Jsoup解析本地xml 案例二
将XML 内容替换一下
<?xml version="1.0" encoding="UTF-8" ?>
<!--
1.填写xml文档的根元素
2.引入xsi前缀. xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
3.引入xsd文件命名空间. xsi:schemaLocation="http://www.itcast.cn/xml student.xsd"
4.为每一个xsd约束声明一个前缀,作为标识 xmlns="http://www.itcast.cn/xml"
-->
<students xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.itcast.cn/xml"
xsi:schemaLocation="http://www.itcast.cn/xml student.xsd">
<student number="persion1">
<name>tom</name>
<age id="888">18</age>
<sex>male</sex>
</student>
<student number="persion2">
<name>lucy</name>
<age>30</age>
<sex>female</sex>
</student>
</students>代码如下:
@Test
public void JsoupDemo2() throws IOException {
Document parse = Jsoup.parse(new File("D:\\GovBuy\\1688\\src\\main\\resources\\student.xml"), "utf-8");
Elements elementsByTag = parse.getElementsByTag("name");
/**
* <name>
* tom
* </name>
* <name>
* lucy
* </name>
*/
Elements elementsByAttribute = parse.getElementsByTag("name"); // 获取所有名为 name 的 标签。
/**
* <name>
* tom
* </name>
* <name>
* lucy
* </name>
*/
Element elementById = parse.getElementById("888");
/**
* <age id="888">
* 18
* </age>
*/
Elements elementsByAttributeValue = parse.getElementsByAttributeValue("number","persion2");
/**
* <student number="persion2">
* <name>
* lucy
* </name>
* <age>
* 30
* </age>
* <sex>
* female
* </sex>
* </student>
*/
Elements elementsByAttributeValue1 = parse.getElementsByAttributeValue("id","888"); // 这里等价于 getElementById("888");
/**
* <age id="888">
* 18
* </age>
*/
}具体玩法,需要根据XML 、HTML结构分析后,再处理。
初级总结:Jsoup解析XML过程涉及到的Java对象 及其常用方法
爬虫就是解析前端的DOM树。Dom树在Jsoup就是Document对象。
通过Jsoup对象解析URL将其转为Document对象,拿到Document对象通过 选择器API 获得指定的Elements集合,再去提取我们需要的Element就可以了。
Jsoup对象:调用Jsoup的入口
- pasre(File file,String charset) 用于解析文件形式的XML、HTML等
- parse(String html) 用于解析String形式的XMl、HTML等
- parse(Url url ,Int timeoutMillis) 用于解析网络形式的XML、HTML等 指定超时时间 可以做小爬虫
- select(String cssQuery) 用于查询项目中所有名叫:cssQuery的标签内容
Document对象:文档对象。代表内存中的Dom树
- getElementsByTag(String tagName):根据标签名称,获取元素集合 即Elments
- getElementsByAtttibute(Stirng key):根据标签的属性名称,获取元素集合 即Elments
- getElementsByAttributeValue(Stirng key):根据属性值,获取元素集合 即Elments
- getElementsById(String id):根据标签id,获取元素集合 即Elments。不常用
Elements:元素Element对象的集合。可以理解成 ArrayList<Element> 去使用
- getElementByTag(String tagName):根据标签名称,获取元素 即Elment
- getElementByAtttibute(Stirng key):根据标签的属性名称,获取元素 即Elment
- getElementByAttributeValue(Stirng key):根据属性值,获取元素 即Elment
- getElementById(String id):根据标签id,获取元素 即Elment。不常用
- get(int index) :获取索引为index的元素对象
- body():将会对原来的Document添加一个<body> </body> 标签
Element:元素对象
- attr(String key):根据属性名称获取属性值 可以获取 href 的连接
- text():获取子标签的纯文本内容 不含"<>","</>"
- html():获取子标签和文本内容的子标签所有内容 包含 "<>","</>"
Node:节点对象
Jsoup高级案例
爬取百度页面的a标签
讲解一下 从Youtube网站上 https://www.youtube.com/watch?app=desktop&v=wzh5TCVnWZQ 看到的Jsoup
爬取 人家连接的超链:
@Test
public void Ahref() throws IOException {
// 获取到DOM树
Document parse = Jsoup.parse(new URL("https://www.baidu.com"),10000);
// 获取到元素集合
Elements elements = parse.select("a");
// 遍历元素集合
for (Element element : elements) {
// 输出 元素中 属性为"href" 的属性值
System.out.println(element.attr("href"));
};
}间接 不完全等价于
@Test
public void AhrefByTag() throws IOException {
// 获取到DOM树
Document parse = Jsoup.parse(new URL("https://www.baidu.com"),10000);
// 获取到元素集合
Elements elements = parse.getElementsByTag("a");
// 遍历元素集合
for (Element element : elements) {
// 输出 元素中 属性为"href" 的属性值
System.out.println(element.attr("href"));
};
}间接 不完全等价于说明
parse.select("a[href]") 选择的是具有 href 属性的 <a> 元素
而 parse.select("a") 选择的是所有 <a> 元素,不考虑是否具有 href 属性。
第一个选择器 选择内容更加具体。
真实实战 - Jsoup获取HTML指定的元素的内容 - 使用CSS选择器爬虫
在Html找到元素
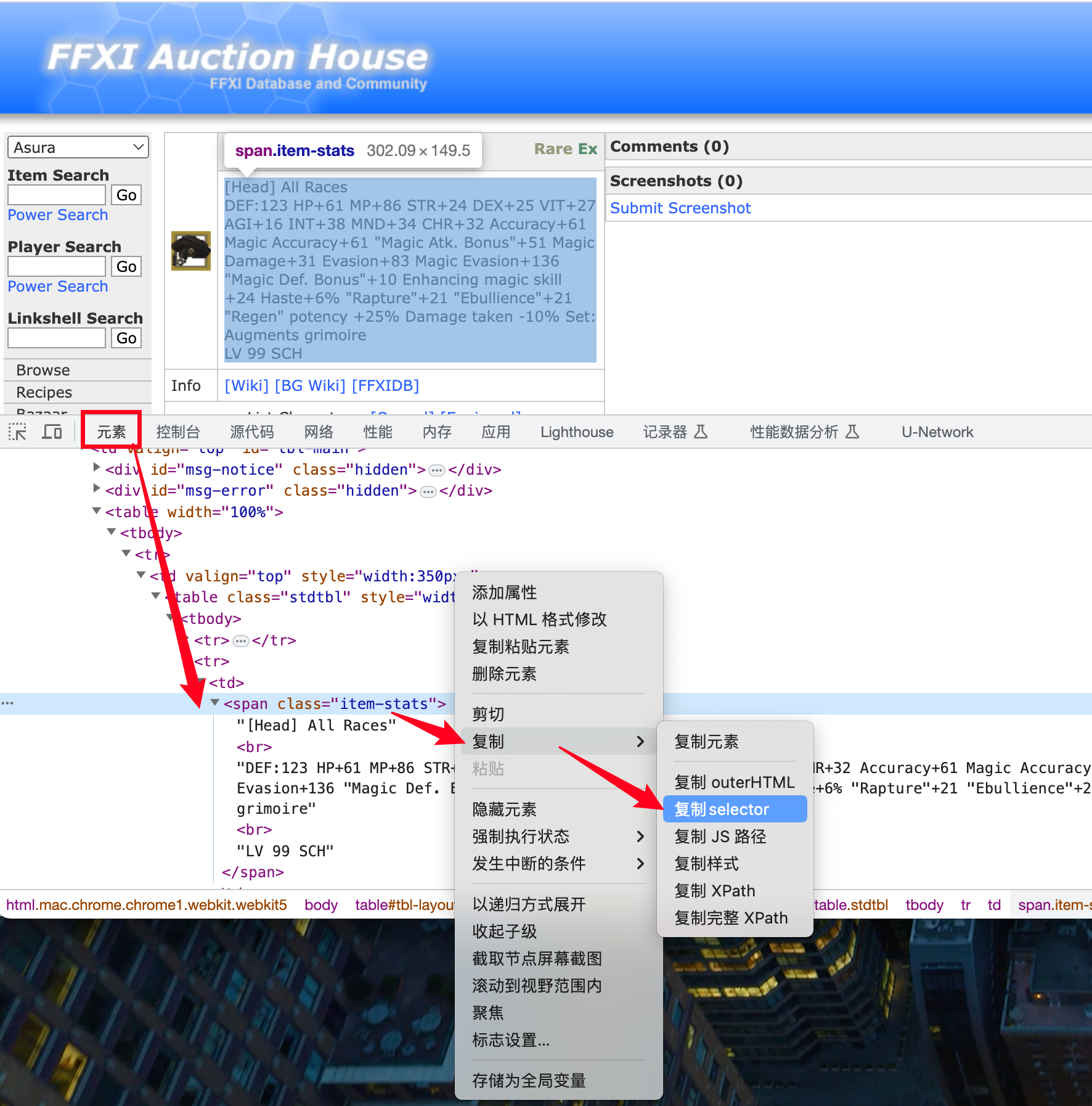
复制selector内容如下:
#tbl-main > table > tbody > tr > td:nth-child(1) > table > tbody > tr:nth-child(2) > td > span使用我们的Java代码获取吧
Integer itemId = 23439;
// 获取到DOM树
Document parse = Jsoup.parse(new URL("https://www.ffxiah.com/item/"+itemId),10000);
// System.out.println(parse); 打印DOM树
Elements select = parse.select("#tbl-main > table > tbody > tr > td:nth-child(1) > table > tbody > tr:nth-child(2) > td > span");
System.out.println("通过复制浏览器Selector获取的路径得到;"+select);
System.out.println("--------------");
// 获取到元素集合
List<String> strings = select.eachText();
// 遍历元素集合
for (String string : strings) {
System.out.println(string);
}打印如下
通过复制浏览器Selector获取的路径得到;<span class="item-stats">[Head] All Races<br>DEF:123 HP+61 MP+86 STR+24 DEX+25 VIT+27 AGI+16 INT+38 MND+34 CHR+32 Accuracy+61 Magic Accuracy+61 "Magic Atk. Bonus"+51 Magic Damage+31 Evasion+83 Magic Evasion+136 "Magic Def. Bonus"+10 Enhancing magic skill +24 Haste+6% "Rapture"+21 "Ebullience"+21 "Regen" potency +25% Damage taken -10% Set: Augments grimoire<br>LV 99 SCH</span>
--------------
[Head] All Races DEF:123 HP+61 MP+86 STR+24 DEX+25 VIT+27 AGI+16 INT+38 MND+34 CHR+32 Accuracy+61 Magic Accuracy+61 "Magic Atk. Bonus"+51 Magic Damage+31 Evasion+83 Magic Evasion+136 "Magic Def. Bonus"+10 Enhancing magic skill +24 Haste+6% "Rapture"+21 "Ebullience"+21 "Regen" potency +25% Damage taken -10% Set: Augments grimoire LV 99 SCH真实实战 - Jsoup获取HTML指定的元素的内容 - 使用XPath爬虫
在Html找到元素
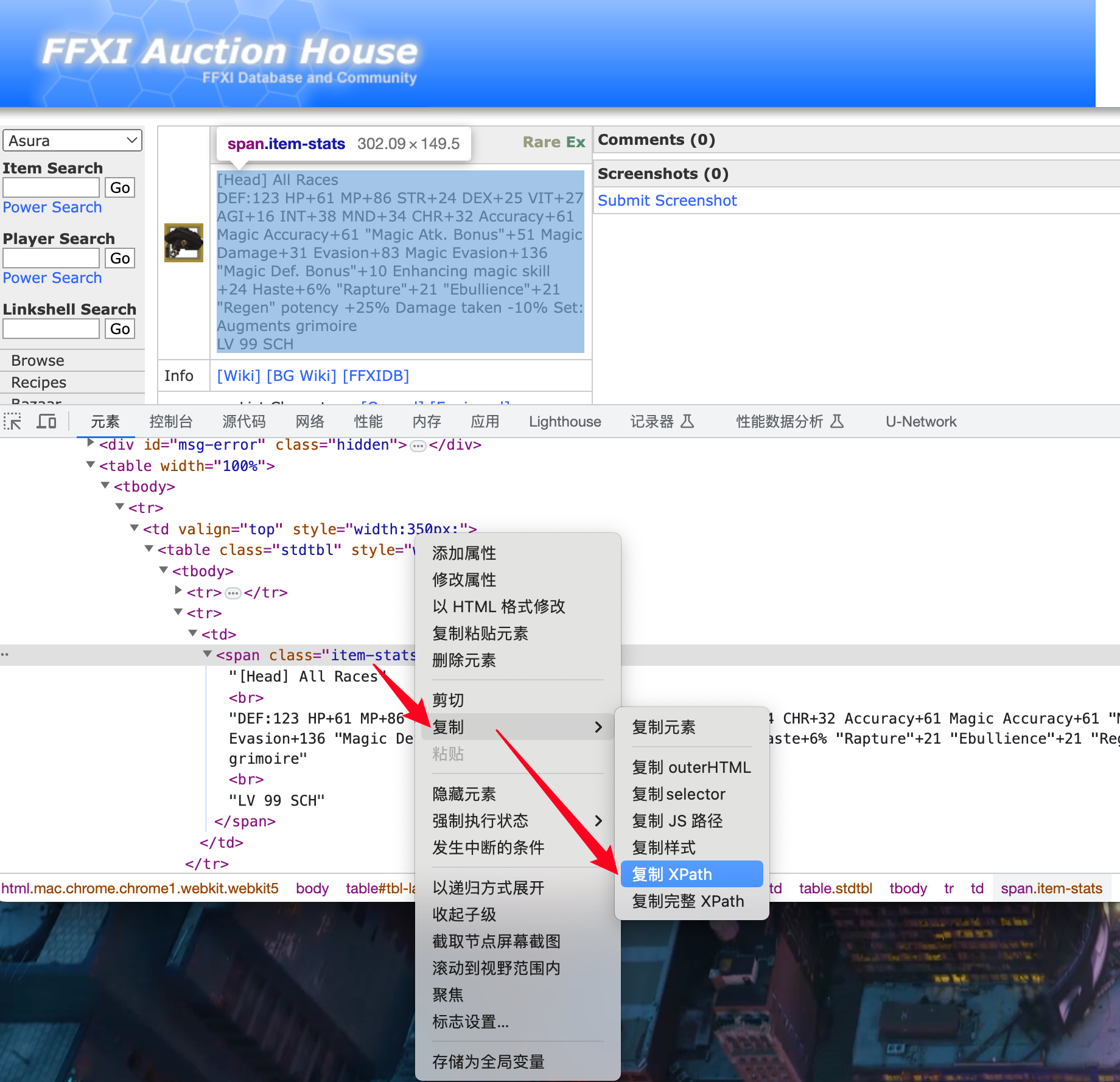
复制的XPath如下:
//*[@id="tbl-main"]/table/tbody/tr/td[1]/table/tbody/tr[2]/td/span代码直接操作:
Integer itemId = 23439;
// 获取到DOM树
Document parse = Jsoup.parse(new URL("https://www.ffxiah.com/item/"+itemId),10000);
// System.out.println(parse); 打印DOM树
Elements select = parse.selectXpath("//*[@id=\"tbl-main\"]/table/tbody/tr/td[1]/table/tbody/tr[2]/td/span");
System.out.println("通过复制浏览器XPath获取的路径得到;"+select);
System.out.println("--------------");
// 获取到元素集合
List<String> strings = select.eachText();
// 遍历元素集合
for (String string : strings) {
System.out.println(string);
}打印如下:
通过复制浏览器Selector获取的路径得到;<span class="item-stats">[Head] All Races<br>DEF:123 HP+61 MP+86 STR+24 DEX+25 VIT+27 AGI+16 INT+38 MND+34 CHR+32 Accuracy+61 Magic Accuracy+61 "Magic Atk. Bonus"+51 Magic Damage+31 Evasion+83 Magic Evasion+136 "Magic Def. Bonus"+10 Enhancing magic skill +24 Haste+6% "Rapture"+21 "Ebullience"+21 "Regen" potency +25% Damage taken -10% Set: Augments grimoire<br>LV 99 SCH</span>
--------------
[Head] All Races DEF:123 HP+61 MP+86 STR+24 DEX+25 VIT+27 AGI+16 INT+38 MND+34 CHR+32 Accuracy+61 Magic Accuracy+61 "Magic Atk. Bonus"+51 Magic Damage+31 Evasion+83 Magic Evasion+136 "Magic Def. Bonus"+10 Enhancing magic skill +24 Haste+6% "Rapture"+21 "Ebullience"+21 "Regen" potency +25% Damage taken -10% Set: Augments grimoire LV 99 SCH
本篇Jsoup总结
程序员在爬虫的时候学会CSS选择器、XPath爬虫就足够应对日常的爬虫需求了!
第三方平台不会及时更新本文最新内容。如果发现本文资料不全,可访问本人的Java博客搜索:标题关键字。以获取最新全部资料 ❤
免责声明: 本站文章旨在总结学习互联网技术过程中的经验与见解。任何人不得将其用于违法或违规活动!所有违规内容均由个人自行承担,与作者无关。
评论(0)