
某项目开发过程任务:获取《物理数据模型清单》。
将PDManer文件中的"数据表"生成"物理数据模型清单",很显然,PDManer是没有输出"物理数据模型清单”这个功能的。
项目急,任务重,我们不得不找一些快速解决方案,代替我们人工复制粘贴”物理数据模型清单“的内容。
操作步骤(MySQL版)- 快速获取物理数据模型清单
1、将PDManer的项目导出为DDL语句。(选择MySQL数据库)
2、创建一个MySQL数据库 'FOR'(库名自定义,下文SQL语句会用到以where = 查询不同库的信息)
3、将DDL语句执行到数据库中。
4、编写自定义的SQL
SELECT
"" AS 'EXCEL序号',
"" AS '系统名称(非DDL信息)',
"" AS '项目名称(非DDL信息)',
"" AS '业务域(非DDL信息)',
UPPER(t1.TABLE_NAME) 表代码,
t2.TABLE_COMMENT AS 表名称,
t2.TABLE_COMMENT AS 表说明,
t1.COLUMN_NAME 字段代码,
SUBSTRING_INDEX(t1.COLUMN_COMMENT, ";", 1) 字段名,
SUBSTRING_INDEX(t1.COLUMN_COMMENT, ";", 1) 字段注释,
UPPER(t1.DATA_TYPE) 字段类型,
t1.CHARACTER_MAXIMUM_LENGTH 长度, -- 修复
IF (t1.COLUMN_KEY = 'PRI', 'TRUE', 'FALSE') AS 是否主键, -- 修复
"FALSE" AS 是否外键,
IF (t1.IS_NULLABLE = 'YES', '是', '否') AS 是否为空, -- 修复
"否" AS 是否主模型,
"" AS 引用编码标准,
"" AS 数据质量要求,
REPLACE (t2.TABLE_COMMENT, '表', '信息') AS 对应业务对象,
SUBSTRING_INDEX(t1.COLUMN_COMMENT, ";", 1) AS 数据项
FROM
INFORMATION_SCHEMA.COLUMNS AS t1
LEFT JOIN information_schema.TABLES t2
ON t1.TABLE_SCHEMA = t2.TABLE_SCHEMA AND t1.TABLE_NAME = t2.TABLE_NAME
WHERE
t1.table_schema = '库名称'
AND t1.table_name IN (
SELECT table_name
FROM information_schema.TABLES
WHERE table_type = 'BASE TABLE' AND table_schema = '库名称'
)
ORDER BY
t1.TABLE_NAME,
t1.ORDINAL_POSITION;执行查询结果DEMO如下:
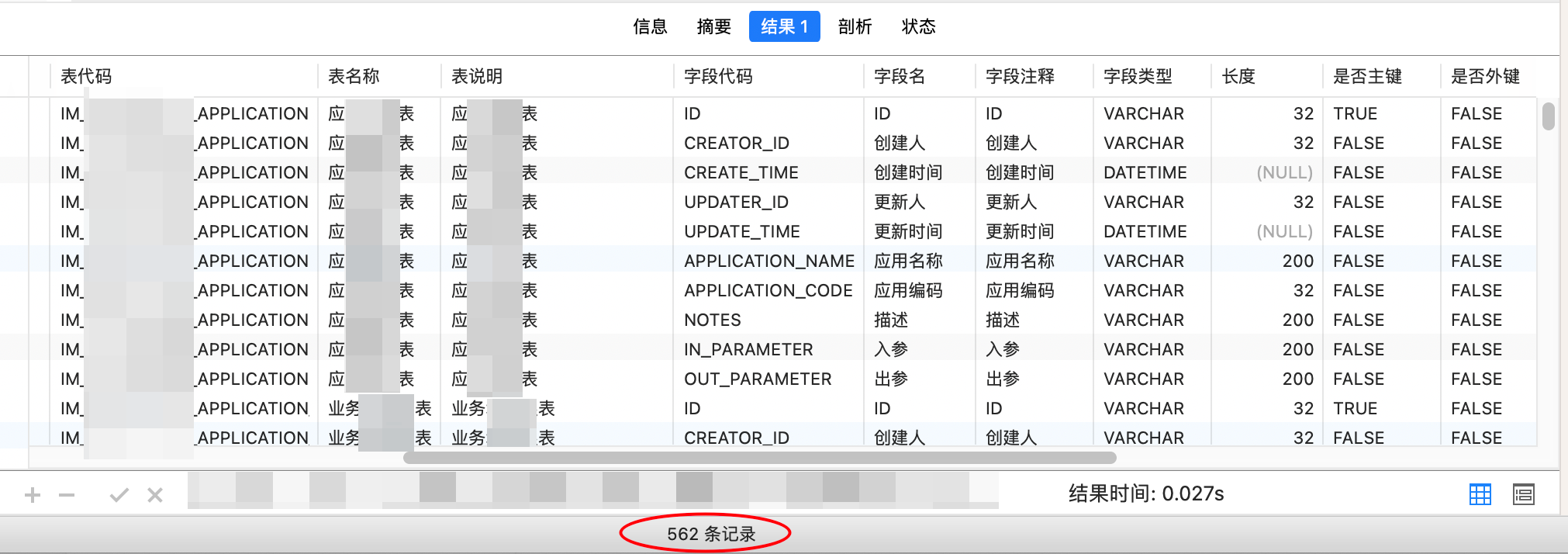
查询到的结果,可以直接复制到Excel了。完结~
下面我将详细的分析,上述SQL,可以查询到的内容。(只针对于MySQL8)
要知道MySQL的数据表信息存储在 information_schema 库的 tables 表中
字段的信息存储在 information_schema库 columns表中
如果我们要获取表的字段信息可以使用(伪代码)select * from information_schema.columns where table_schema = "你的数据库名"
如果要获取表信息的话,我们可以关联查询information_schema.tables,条件是 t1.TABLE_NAME = t2.TABLE_NAME。
【重点】库information_schema 表 tables 我们能获取的元素
| 字段名 | 注释 | 示例数据 |
|---|---|---|
| TABLE_CATALOG | 表所属的目录名 | NULL |
| TABLE_SCHEMA | 表所属的数据库名 | 最终幻想11数据库 |
| TABLE_NAME | 表名 | 用户登录记录表 |
| TABLE_TYPE | 表类型,可能的值为 BASE TABLE、VIEW 或 SYSTEM VIEW | BASE TABLE |
| ENGINE | 存储引擎 | InnoDB |
| VERSION | 存储引擎的版本号 | 10 |
| ROW_FORMAT | 行格式,可能的值为 Fixed、Dynamic、Compressed、Redundant、Compact 或 Paged | Dynamic |
| TABLE_ROWS | 表中行的数量 | 1000 |
| AVG_ROW_LENGTH | 平均每行的长度 | 50 |
| DATA_LENGTH | 表中数据的长度 | 50000 |
| MAX_DATA_LENGTH | 最大数据长度 | 0 |
| INDEX_LENGTH | 所有索引占用的空间大小 | 20480 |
| DATA_FREE | 未使用的空间大小 | 0 |
| AUTO_INCREMENT | 自增长列的下一个值 | 1001 |
| CREATE_TIME | 表的创建时间 | 2023-06-26 10:00:00 |
| UPDATE_TIME | 表的最后更新时间 | 2023-06-26 10:30:00 |
| CHECK_TIME | 表的最后检查时间 | NULL |
| TABLE_COLLATION | 表的字符集和排序规则 | utf8mb4_general_ci |
| CHECKSUM | 表的校验和 | NULL |
| CREATE_OPTIONS | 表的创建选项 | NULL |
| TABLE_COMMENT | 表的注释 | 我是表的注释 |
【重点】库information_schema 表 COLUMNS 我们能获取的元素
| 字段名 | 注释 | 示例数据 |
|---|---|---|
| TABLE_CATALOG | 表所属的目录名称 | NULL |
| TABLE_SCHEMA | 表所属的数据库名称 | 我是数据库名 |
| TABLE_NAME | 表名称 | 我是数据表名 |
| COLUMN_NAME | 列名称 | USER_NAME |
| ORDINAL_POSITION | 列在表中的位置 | 1 |
| COLUMN_DEFAULT | 列的默认值 | NULL |
| IS_NULLABLE | 列是否允许为空 | YES 或者 NO |
| DATA_TYPE 注意:COLUMN_TYPE 不同点是,不包含长度 | 列的数据类型 | varchar 建议使用UPPER(DATA_TYPE) 转为大写 |
| CHARACTER_MAXIMUM_LENGTH | 列的字符最大长度 | 64 |
| CHARACTER_OCTET_LENGTH | 列的字节最大长度 | 192 |
| NUMERIC_PRECISION | 数值列的精度 | NULL |
| NUMERIC_SCALE | 数值列的小数位数 | NULL |
| DATETIME_PRECISION | 日期时间列的精度 | NULL |
| CHARACTER_SET_NAME | 列的字符集名称 | utf8mb3 |
| COLLATION_NAME | 列的字符集排序规则名称 | utf8mb3_tolower_ci |
| COLUMN_TYPE | 列的数据类型和长度 | varchar(64) |
| COLUMN_KEY | 列的键类型 | |
| EXTRA | 列的额外信息 | |
| PRIVILEGES | 列的权限 | select,insert,update,references |
| COLUMN_COMMENT | 列的注释 | 表所属的目录名称 |
| GENERATION_EXPRESSION | 列的生成表达式 | NULL |
| SRS_ID | 空间参考系统的 ID | NULL |
至于说需要其他字段,考虑问下GPT MySQL是否有相关的信息
特殊说明:
上述文章均是作者实际操作后产出。烦请各位,请勿直接盗用!转载记得标注原文链接:www.zanglikun.com
第三方平台不会及时更新本文最新内容。如果发现本文资料不全,可访问本人的Java博客搜索:标题关键字。以获取最新全部资料 ❤
免责声明: 本站文章旨在总结学习互联网技术过程中的经验与见解。任何人不得将其用于违法或违规活动!所有违规内容均由个人自行承担,与作者无关。
第三方平台不会及时更新本文最新内容。如果发现本文资料不全,可访问本人的Java博客搜索:标题关键字。以获取最新全部资料 ❤
免责声明: 本站文章旨在总结学习互联网技术过程中的经验与见解。任何人不得将其用于违法或违规活动!所有违规内容均由个人自行承担,与作者无关。