
索引 是 数据表 快速搜索的关键。MySQL索引的建立对于MySQL的高效运行是 很重要的。对于数据表中只有少量的数据,没有合适的索引对查询速度影响不是很大,但是,当随着数据量的增加,性能会急剧 下降。当创建索引带来的好处多大于缺点的时候,才是最优的选择~
查看某个表的索引设置
现在一般有使用可视化界面查看索引了,SQL查询也保留下吧。
# 查看某个表的索引
show index from 你的表名;前言
本文会介绍:索引类型、索引存储结构,最后附上我的个人见解,值得一看!
各大索引类型介绍(必须要掌握的知识)
| 索引类型 | 说明 | 是否允许重复 | 是否允许 NULL | 特点与使用场景 |
|---|---|---|---|---|
| 主键索引(PRIMARY KEY) | 用于唯一标识表中一行数据;定义主键时自动创建。 | 不允许重复 | 不允许为空 | 每张表只能有一个主键;在 InnoDB 中为聚簇索引。 |
| 唯一索引(UNIQUE) | 保证列值唯一性,但可有一个 NULL(视引擎而定)。 | 不允许重复 | 允许空值(MySQL中允许多个NULL) | 常用于账号、身份证号等字段。 |
| 普通索引(INDEX) | 最常见的索引,无唯一性约束。 | 允许重复 | 允许空值 | 提升过滤查询效率。 |
| 联合索引(Composite Index) | 基于多个字段建立的索引。 | 视字段而定 | 视字段而定 | 用于多条件查询时能有效提升性能。存在“最左前缀匹配”原则。 |
| 全文索引(FULLTEXT) | 用于对文本内容(CHAR、VARCHAR、TEXT)进行分词匹配。 | — | — | 支持自然语言搜索、布尔模式搜索。InnoDB、MyISAM支持。 |
| 空间索引(SPATIAL) | 用于GIS空间数据类型(geometry 等)。 | — | — | 用于地理坐标、地图位置查询。 |
索引使用方式(本节均是必须要掌握的知识)
索引命名
很多人都会忽略标准化的命名。我给大家整理一些标准的索引命名!
我下面给的案例,命名你全大写、小写都可以。这个看你自己喜好。(PS:我习惯了达梦数据库开发3年后,SQL全是大写的!)
假设表名称是:user
| 场景 | 索引定义 | 推荐命名 | 备注 |
|---|---|---|---|
| 主键 | PRIMARY KEY (id) | PK_表名_ID | 无需人工配置! |
唯一约束 | CREATE UNIQUE INDEX UK_user_email ON | UK_EMAIL | 唯一性校验 |
普通单列索引 | CREATE INDEX IDX_user_name ON | IDX_ | 最常用的!必须遵守 |
联合索引 | CREATE INDEX IDX_user_status_createdat ON | IDX_ | 命名也要遵循字段顺序从左到右 |
| 外键索引 | ALTER TABLE 表名2 ADD CONSTRAINT FK_order_userid FOREIGN KEY(user_id) REFERENCES user(id); | FK_ | 逻辑关联外键 (因为阿里开发规范禁止使用外键,我接触的互联网项目也没用过,这里不做约束了) |
索引使用分类
索引使用一般分为:单字段索引、多字段索引(联合索引)
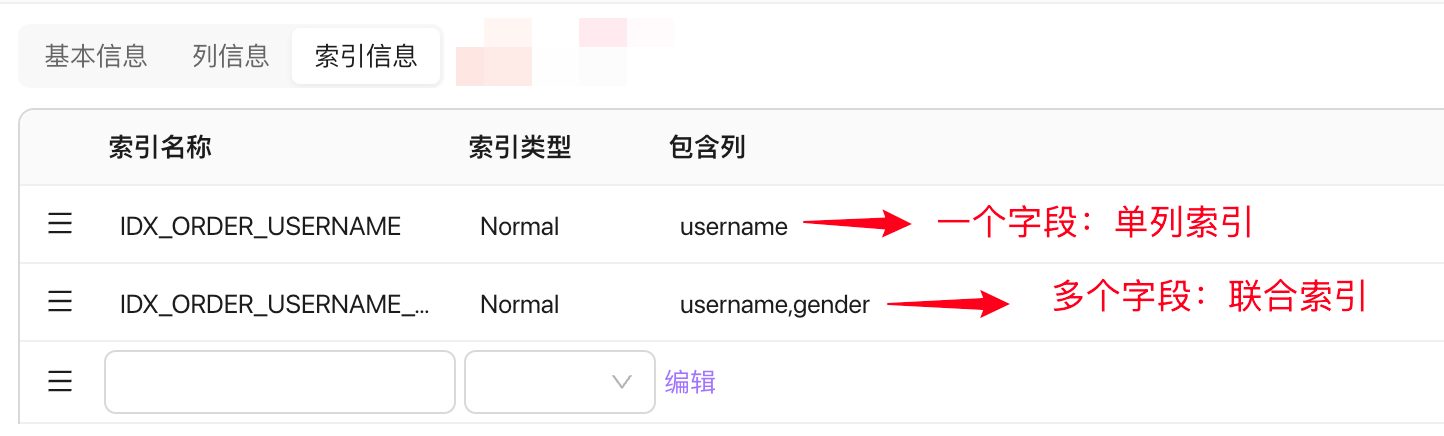
单列索引
单列索引 :一个字段的索引就是单列索引,一个表可以有多个单列索引!
多字段索引 - 联合索引
联合索引 :多个字段索引组成的索引就是联合索引,一个表也可以有多个联合索引!
日常需要优化的SQL一般都是通过联合索引进行优化的。
联合索引是由多个字段按顺序组合而成的索引,比如 (A, B, C)。
在查询时,MySQL 会依据“最左前缀”原则来决定是否使用索引:
如果查询条件包含最左边的列 A(比如 WHERE A = '开启'),索引是可以生效的;
但如果跳过最左列,只使用 B 或 C 进行筛选,索引就无法使用。
组合索引使用原则(重点)
| 概念 | 说明 |
|---|---|
| 最左前缀原则 | 在联合索引 (a, b, c) 中,如果查询条件是 a 或 (a, b),可以使用索引;若只用 b,则无法命中。 |
| 覆盖索引 | 当查询列被索引完全覆盖时,无需回表,效率最高。 |
| 索引下推 | MySQL 5.6+ 对联合索引支持的优化手段,可以在索引层提前过滤非匹配记录,减少回表次数。 |
举例组合索引场景使用说明(重点)
前置条件:一张表配置了联合索引 (A, B, C)
| 查询语句 | 是否能用联合索引索引 | 说明 |
|---|---|---|
WHERE A = 1 | ✅ 能用 | 匹配 A,满足最左前缀 |
WHERE A = 1 AND B = 2 | ✅ 能用 | 匹配 A、B |
WHERE A = 1 AND B = 2 AND C = 3 | ✅ 完全使用索引 | 匹配整组字段 |
WHERE B = 2 | ❌ 不能用 | 跳过了最左列 A |
WHERE B = 2 AND C = 3 | ❌ 不能用 | 同上 |
WHERE A = 1 AND C = 3 | ⚠️ 可能部分使用 | A 能命中索引,但 C 需要再回表过滤 |
WHERE A LIKE '开%' | ✅ 可用 | 左前缀仍匹配 |
WHERE A LIKE '%启' | ❌ 不可用 | 失去前缀匹配特性 |
索引排序(可忽略)
通常不必为升序与降序分别建立索引。所以大家基本不需要关注这里。默认升序ASC就好了
索引的存储结构(有兴趣就记个大概即可)
绝大多数场景,普通玩家用B+树索引就够玩了。其他截止我5年经验使用场景,实际用不到其他索引结构类型的
| 索引结构类型 | 实现方式 | 说明与适用场景 |
|---|---|---|
| B+Tree 索引 | 默认结构 | 绝大多数 MySQL 索引(包括主键索引和普通索引)都基于 B+Tree 结构,适合范围查询与排序。 |
| Hash 索引 | Memory 引擎支持 | 通过哈希表快速定位,适合等值查询(=),不支持范围查询。 |
| R-Tree 索引 | 空间索引结构 | 用于多维空间数据存储(GIS),支持地理范围查找。 |
| Full-Text 索引 | 倒排索引结构 | 主要面向文字内容检索。 |
| Clustered Index(聚簇索引) | InnoDB 主键使用 | 数据行按主键顺序存储,一个表仅有一个。 |
| Secondary Index(非聚簇索引) | InnoDB 非主键索引 | 保存主键的引用(指针),通过主键二次查找数据。 |
关于索引的一些个人理解(建议阅读)
InnoDB 中索引确实存储在物理文件中,其中主键索引是聚簇索引,数据行与索引存储在同一结构中,而辅助索引则独立存在。
建立过多无用索引会占用额外存储空间,并增加插入、更新、删除操作的维护开销。
相比较而言,有索引的表在写操作时性能会略低,因为数据库需要同时更新索引结构。
在查询优化中,索引应针对高频查询条件或连接字段建立;对于多条件查询,可考虑联合索引,但需遵循最左前缀规则,避免冗余与滥用。
一个SQL查询究竟需不需要索引,还是需要评估业务系统数据量、业务实时紧急程度、高频性来决定。如果确定了需要索引优化,请看本章最后一段Explain的使用。
索引引用实战
第三方平台不会及时更新本文最新内容。如果发现本文资料不全,可访问本人的Java博客搜索:标题关键字。以获取最新全部资料 ❤
免责声明: 本站文章旨在总结学习互联网技术过程中的经验与见解。任何人不得将其用于违法或违规活动!所有违规内容均由个人自行承担,与作者无关。