
什么是智能体Agent与大模型?
首先看“大模型”是什么
✅ 定义: 指具备通用自然语言理解和生成能力的人工智能模型。比如通义千问、GPT、Claude、Gemini 等,都属于「大语言模型(LLM)」。
✅ 核心作用:
- 理解人类指令(语言输入)
- 生成逻辑清晰的文字或代码输出
- 可以推理、总结、创意写作、分析等等
👉 简单说,它是“AI 的大脑”。
再看“智能体(AI Agent)”
✅ 定义: 智能体是在大模型基础上,加上一层“目标任务和操作能力”的封装。
它知道自己要做什么,可以主动调用工具、访问外部系统、执行实际任务。
✅ 特点:
- 拥有角色定位(比如:日报总结专家、代码助手、知识管理助手)
- 能调用工具(搜索网页、访问数据库、调用API、执行动作)
- 能持续对话或决策(不是一次性回答,而是持续任务化)
👉 简单说,它是“用大模型驱动的专业助理或执行器”。
大模型与Agent关系可以这样比喻
| 类比对象 | 名词 | 作用 |
|---|---|---|
| 人类 | 大脑 | 负责思考和理解(对应“大模型”) |
| 职业角色 | 职场中的你 | 带着任务和工具去执行(对应“智能体”) |
所以:
大模型 = AI 的“核心智能”
智能体 = 基于大模型的“应用化外壳”,让模型有目标、有工具、有场景
🧩 四、日常例子
| 使用场景 | 智能体Agent名称 | 依托大模型 | 输出功能 |
|---|---|---|---|
| 日报/周报总结 | 日报与周报总结专家 | 通义大模型 | 从飞书文档提取并结构化日报 |
| 编码搭档 | IDEA 灵码助手 | 通义大模型 | 分析代码、生成提交说明 |
| 法律顾问 | 法律智能体 | 通义大模型 | 法条解释与风险提示 |
什么是 LLM 和 VLM?
LLM (Large Language Model,大语言模型)专注文本
LLM 是指拥有非常多参数(通常在数十亿甚至上百亿)的深度学习模型,主要用于**自然语言处理(NLP)**任务。它通过大规模文本数据训练,能够理解和生成自然语言。
VLM (Vision-Language Model),视觉-语言模型结合视觉和语言。
VLM 是同时具备图像感知(计算机视觉,CV)与文本理解/生成能力的多模态模型。它不仅能看懂图片,还能结合文字生成回答或描述。
更高级的模型会融合视觉、语言、音频甚至动作数据 → 多模态能力,让 AI 更接近人类感知方式。
大模型标签含义
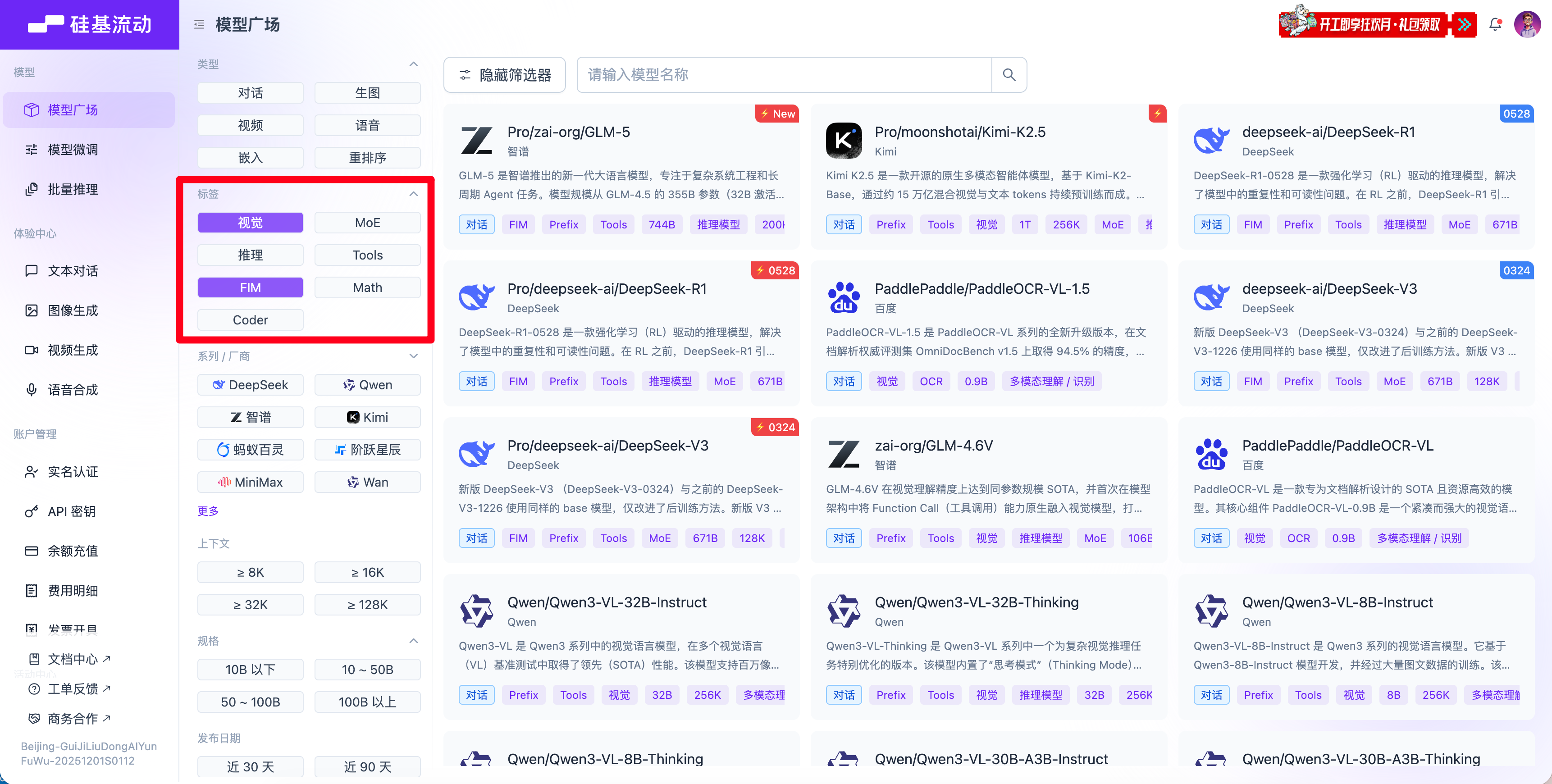
| 标签 | 全称 / 核心含义 | 关键能力与应用场景 | 代表模型示例 |
|---|---|---|---|
| 视觉 (Vision) | 多模态视觉能力 | 图像理解、图像生成、OCR、视觉问答、视频分析 | GPT-4V、Qwen-VL、Gemini Pro Vision |
| MoE | Mixture of Experts(混合专家) | 万亿级参数、高效推理、高吞吐、成本优化 | GPT-4、Mixtral 8x7B、Llama 3 MoE |
| 推理 (Reasoning) | 逻辑与多步推理 | 数学题、逻辑题、规划任务、复杂问题拆解 | DeepSeek-R1、Qwen 2.5 72B、Claude 3 |
| Tools | 工具调用能力 | 计算器、搜索引擎、代码解释器、API 调用、实时信息获取 | GPT-4o、Claude 3 Opus、豆包 AI |
| FIM | Fill-in-the-Middle(中间补全) | 代码中间插入、补全已有代码片段、符合开发习惯 | CodeLlama、StarCoder、DeepSeek-Coder |
| Math | 数学专项能力 | 算术、代数、几何、微积分、公式推导、应用题 | Qwen Math、DeepSeek Math、GPT-4o |
| Coder | 代码专项能力 | 代码生成、调试、重构、多语言支持、开发辅助 | CodeLlama、DeepSeek-Coder、StarCoder2 |
如何在AI编辑器如何选择?
这一块不必太纠结,使用前,看看大致符合自己的选择一下就OK的。
Trae
选择不同的智能体,来解决你不同层次的需求问题
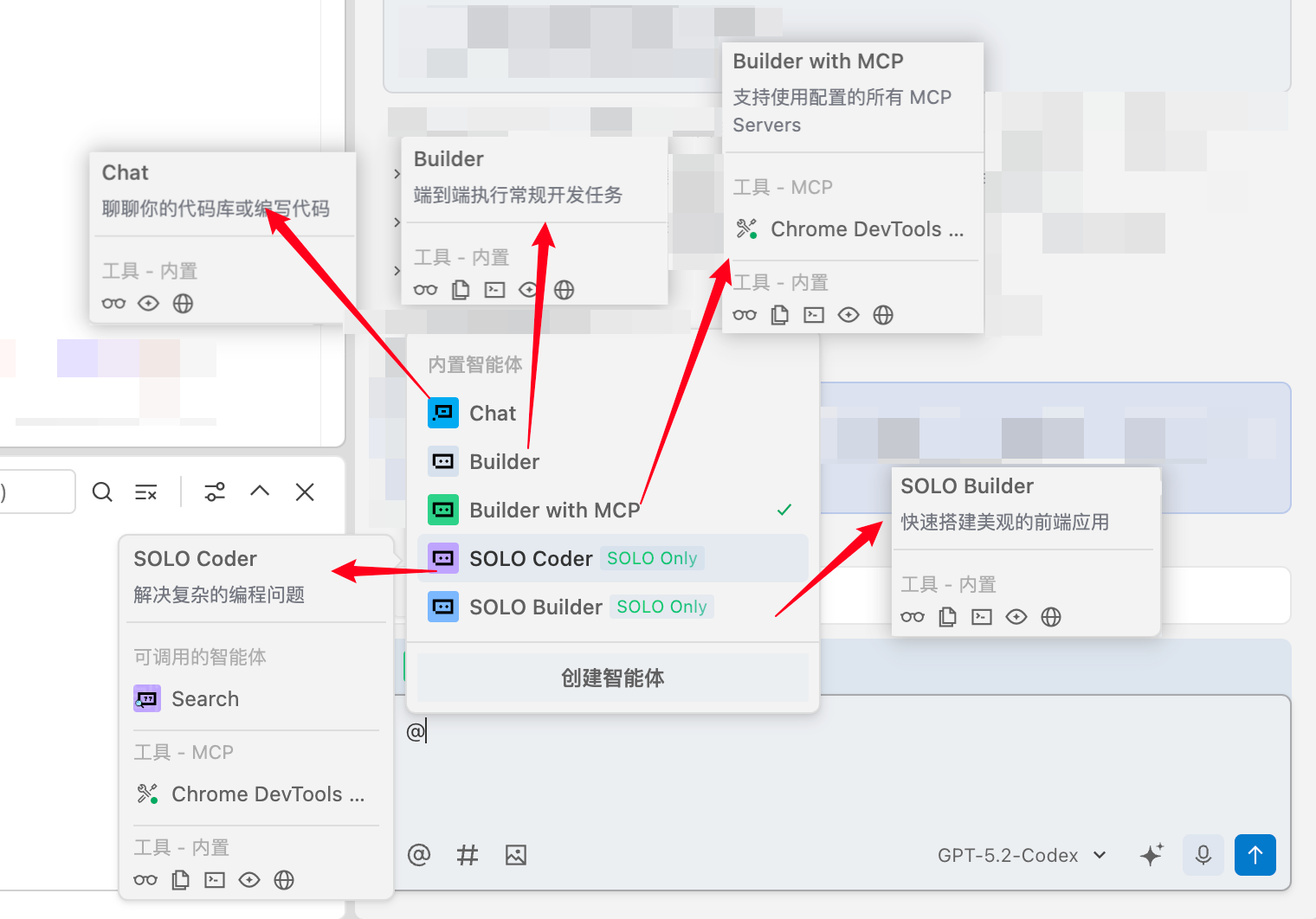
Copilot
| 模式 | 作用定位 | 典型使用场景 | 交互方式 | 优势特点 |
|---|---|---|---|---|
| Agent | 智能执行助手 | 直接生成或修改代码、运行脚本、批量处理任务 | 你下指令,它直接帮你做并返回结果 | 高度自动化,能一步到位完成任务 |
| Plan | 任务规划师 | 需求分析、步骤分解、项目路线图 | 你描述目标,它帮你拆分成多步骤计划 | 逻辑清晰,可作为后续开发的参考 |
| Debug | 问题诊断专家 | 代码报错分析、日志排查、性能优化建议 | 你贴错误信息,它帮你定位并提出修复方案 | 针对问题定向分析,减少调试时间 |
| Ask | 普通问答助手 | 学习知识点、查资料、解释概念 | 正常问问题,它给出解释或资料链接 | 简单直接,不涉及执行操作 |
💡 使用建议:
- 开发改代码 → Agent
- 尚未开始,先规划 → Plan
- 程序出问题 → Debug
- 普通查资料 → Ask
AI编辑器 - Skill - 技能
Trae官方介绍Skill:https://docs.trae.cn/ide/skills
一个技能可以被视为提供给智能体的一套 “专业能力说明书”(类似用户手册或操作指南)。在执行任务时,智能体可以按需加载相应的技能,从而增强其对任务的理解与执行能力。
主要特点
- 结构化
一个技能对应一个 SKILL.md
文件,文件中以结构化的方式描述完成某一类任务所需的信息,例如:任务目标与适用场景;关键约束与注意事项;推荐流程或操作步骤;可选的脚本、模板或示例。
- 动态按需加载
智能体不会在任务开始时一次性读取所有技能的完整内容。在执行任务前,智能体会先扫描所有技能的简要描述,仅当判断当前任务与某个技能高度相关时,才会加载该技能的详细内容。这种按需加载机制可以有效减少上下文中的 Token 消耗、避免无关信息干扰智能体的决策。
使用场景
- 保证输出结果的一致性与规范性
需要智能体在不同时间、不同任务中,始终按照既定标准输出结果。例如,将统一设计规范、执行团队标准、保持品牌一致性或确保代码符合项目约定等要求封装为技能,从而将隐性的个人或团队标准转化为显式、可复用的专业能力,最终使输出结果更加稳定、可控。
- 自动化重复性工作流
需要频繁执行相同或高度相似的多步骤任务。例如,对于测试流程、代码规范检查、常规数据分析等难以避免的日常工作,可以将既有的 SOP 封装为技能。一旦相关任务被触发,智能体即可自动按照定义好的流程执行,从而减少重复的指令输入,提升效率。
- 总结与共享专业能力
总结个人经验或团队规范,并在更大范围内复用。例如,将技能在社区、交流群等公共平台进行分享,从而在不同的智能体、项目、团队间复用相同的技能。
技能 vs 其他功能
- 技能 vs 规则
规则采用全量加载机制,一旦开启对话,所有规则都会被注入并持续占用上下文窗口;技能则采用按需加载机制,仅在实际需要被调用时才加载到上下文中,从而显著降低 Token 消耗。
- 技能 vs MCP Server
技能用于向 TRAE 描述如何完成任务,而 MCP Server 负责向 TRAE 提供可以调用的工具。
例如,TRAE 可以通过 Playwright MCP Server 获得页面操作等自动化测试能力;而对应的技能则用于约定测试工程结构、页面对象模型(POM)设计规范,以及常见测试用例的编写和执行流程,从而引导 TRAE 在正确的上下文中高效调用这些能力。
Trae官方推荐的10大Skill
https://docs.trae.cn/ide/top-10-recommended-skills-for-development-scenarios
第三方平台不会及时更新本文最新内容。如果发现本文资料不全,可访问本人的Java博客搜索:标题关键字。以获取最新全部资料 ❤
免责声明: 本站文章旨在总结学习互联网技术过程中的经验与见解。任何人不得将其用于违法或违规活动!所有违规内容均由个人自行承担,与作者无关。